Description
三伏天刚过,深圳的夏天依旧炎热,时不时下着的暴雨,望着窗外的乌云,感受下磅礴的的大雨,可以呆呆的这么看一天。一年的光景,进度已经过半了,似乎什么也没有做,忙忙碌碌的一年,追逐着 ai 的新技术,好像到头来都是在等业界开源,兜兜转转的,前端的新技术进入 2023 年声音,更加少了,互联网的红利已经退了快两年了,元宇宙和 ai 轮番上阵,以前跟踪的博客分享越来越少,更不要说前端领域了,也越来越没有人讨论了。就业市场也是一片萧瑟,去年求职时深圳已经是一片红海,北上还好不少,到如今市场还是没有喘过气来。大部分人都忙着干活,投入产出比,那技术的方向呢?在前端方向是要少很多了,但是目光可以看向更远。比如现在的 aigc 方向。

静止的 2d 图片如何让它动起来,更加吸引人呢?根据文字生成视频目前的应用非常少,大部分还在研究阶段,现在更多的是数字人类型的口播,通过提供一段文字和指定的人物形象,输出播报员效果的视频,还有另外一种是视频的风格迁移,类似 midjourney 的风格迁移,将一段视频的风格迁移到另外一段视频上,玩玩是挺好的,还有新 controlnet 也有这个功能。只是图片要如何动起来呢?其实还有另外一个方向,3d-photo 这已经是前几年的概念了,指的是图片转为有动画效果的 3d 图像,成功的让图片动起来。
3D-Photo-Inpainting
这是 2021 年的开源项目,通过输入一张 RGB-D 图像,输出分层的深度图像,并填补原始图像中缺少的颜色和深度。可以先看看效果:3d-动画

可以看到原本不动的小孩,会随着视角的变化,不断的变化,很是生动形象。3D-Photo-Inpainting 先通过输入的图像生成对应的景深图,景深图像的生成有两种方式,一种是通过 BoostingMonocularDepth,也是 3D-Photo-Inpainting 的默认方式,还可以通过 MiDaS 生成,只是试了几次后 MiDaS 效果更佳好。生成景深图后,只能知道前景和后景的关系,但是前景移动会形成空缺,要如何处理呢?还需要再结合项目提供的三个模型:边修复网络、颜色修复网络、深度修复网络处理,具体算法可以自行去了解。
3D-Photo-Inpainting 项目输出效果不错,只是有个严重的问题,输出效果太耗时间了,调整参数优化后,3d 视频的生成要等待 2min 多,这个时间对于用户来说是不可接受的,提前加载模型,最后也要 1min 多。后面改了下实在没有很好的办法,只能另找其他的方案了。
后续发现一个竞品项目 leiapix,居然能够很好的实现 3d 效果,而且关键是加载时间不到 10s,这个效果是如何做到的,比 3D-Photo-Inpainting 快太多了,后面通过开发者工具查看发现是采用了 depthy 项目的方式。
depthy
depthy 是一个在线的 3d 图片生成工具,可以将 2d 图片转为 3d 图片,可以看看效果,可以跟着鼠标动,交互性很好,只是都是左右上下动,没有 3D-Photo-Inpainting 效果好,缺少前景的深度变化。项目也是开源,地址 depthy,可以一探究竟。
项目采用 angular2 框架开发,工程化是 grunt 方式,可以说是快 10 年前的方式,最后本地也没有启动成功。不过分析代码流程,还是可以发现,虽然用了一张原图和其景深图就能很好的实现 3d 效果,究竟是如何实现的呢?难道是中间有调用远程服务的接口?类似 segment-anything 的 demo 效果一样,需要先调用生成 tensor 对象。
后面发现居然是使用 PIXI 来生成并渲染 3d 效果,可以看看其代码流程:
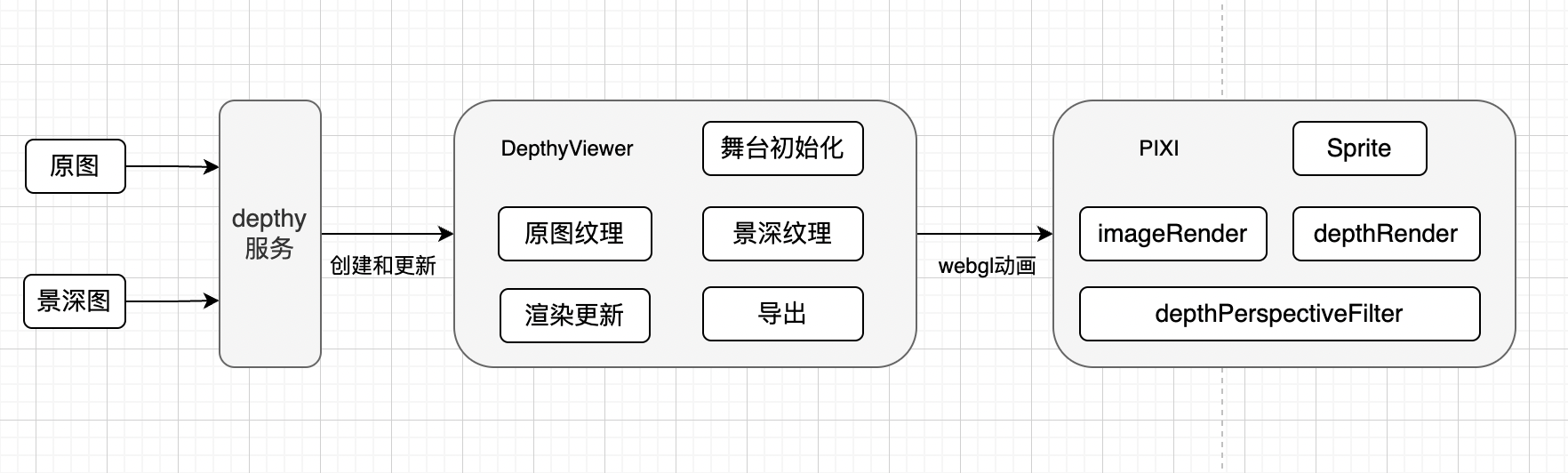
应用通过 depthy 服务调用来实现 3d 效果,包括更新原图、景深图、缓存、重置效果等操作。其中 DepthyViewer 是整个操作的核心,处理纹理、舞台合成、渲染动画的更新还包括导出等功能。DepthyViewer 里面会初始化 PIXI.WebGLRenderer 渲染器和舞台、原图的 RenderTexture、景深的 RenderTexture。通过更新渲染器、舞台最后来实现渲染器的更新。那最后景深图要如何将 3d 动画动起来呢?其实用到了 PIXI 的 filter 功能。filter 是一种特殊的着色器,它将处理后效果应用于输入纹理并写入输出渲染目标,可以理解为类似中间件效果,通过 filter 可以编写新的纹理效果来更新输出。这里值得的关注的是 depthPerspectiveFilter 里面对图像的再次处理,这里举个例子,比如下面的原图和景深图:


景深图
上面处理流程有一步是特别重要的,如何生成呢?在 3D-Photo-Inpainting 项目里面,有两种生成景深图的方式:
- BoostingMonocularDepth 默认处理方式,可以从单个图像生成高分辨率深度图,提供更高的细节,支持数百万像素深度图
- Midas 是一种机器学习模型,可以根据任意输入图像估计深度
BoostingMonocularDepth 提供了更高的深度细节,但是对于我们的 3d 动效不用太过细腻,最后使用 MiDaS。目前是 V3.1 模型,并提供了多种方式的模型
关键代码处理如下:
# 加载模型、神经网络等
model, transform, net_w, net_h = load_model(device, model_path, model_type, optimize, height, square)
# 通过神经网络处理图像
image = transform({"image": input_image})["image"]
# 通过 V3.1 模型输出深度数据
prediction = model.forward(sample)
# 将数据按照最大到最小值映射阶梯
out = max_val * (depth - depth_min) / (depth_max - depth_min)通过 V3.1 模型输出对应的景深图,默认会使用 applyColorMap 按照 cv2.COLORMAP_INFERNO 输出彩色图,如果需要灰度图,需要配置 grayscale=False 来关闭掉。
3D 化
景深图获取到,要如何让图片有 3d 形态的运动呢?3D-Photo-Inpainting 会通过三个网络修复。而看遍 depthy 代码,没有使用到模型,那是如何处理的?可以看到上面 depthy 的流程图,最后是用 PixiJS 来绘制的,采用了 filter 的功能。但是原本的方式只有 x、y 轴方向的运动,缺少深度方向的变化,要如何让前景动起来,后景不变呢,主要代码设计如下:
vec3 ray_origin = vec3(uv.x - 0.5, uv.y - 0.5, +1.0);
vec3 ray_direction = vec3(uv.x - 0.5, uv.y - 0.5, -1.0);
// 省略部分代码
ray_direction /= float(step_count);
for (int i = 0; i < step_count; i++) {
ray_origin += ray_direction;
vec2 vFlipUV = (ray_origin.xy + 0.5) * vec2(1, -1) + vec2(0, (dimensions.y - 1.0) / dimensions.y);
// 获取景深图的的 x 值
float scene_z = texture2D(displacementMap, vFlipUV).x;
if (ray_origin.z < scene_z) {
if (scene_z - ray_origin.z < hit_threshold) return texture2D(uSampler, ray_origin.xy + 0.5).rgb;
ray_origin -= ray_direction; // step back
ray_direction /= 2.0; // decrease ray step to approach surface with greater precision
}
}
return texture2D(uSampler, ray_origin.xy + 0.5).rgb;上面代码可以看到,每次迭代都会叠加 ray_direction,让 ray_origin.z 越来越小,然后每次迭代中对比 ray_origin.z 和当前景深。对于前景物体,其景深图会偏白色,背景偏灰色,scene_z 会偏大,会在迭代中通过 ray_direction /= 2.0 降低 ray_direction 大小,最使得后景的物体,其 ray_origin.xy 变化,而前景基本不变,从而导致前景和后景分离。最后呈现效果是前景不动,而后景在不断的缩小放大。
这里面涉及项目内容多,就不详细介绍了,大致是通过 webgl 来更新图像。
cv 处理
上面生成的 3d 效果图还有个严重问题,如下图所示,图像的动画过程会导致部分区域割裂,黑色部分非常明显,比如右下角的手部,出现了明显的黑带。3D-Photo-Inpainting 里面通过模型生成来填补的方式最好,但是速度过于慢,那要如何处理?

前景和后景之间过渡太过生硬了,纹理渲染的时候过渡地方,会出现撕裂情况。既然动画是根据景深图来控制的,那可以用 opencv 来优化深度图,前后景的衔接部分进一步模糊处理。
最后处理方式如下:
mask = cv2.morphologyEx(mask, cv2.MORPH_OPEN, kernel)
mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel)
dilate = cv2.morphologyEx(mask, cv2.MORPH_DILATE, kernel)
blur = cv2.GaussianBlur(dilate, (155, 155), 0)上面是核心处理方式,通过 cv 的开操作和闭操作,来去除掉细小的区域,然后再膨胀,适当增加前景大小,最后通过高斯模糊,将过渡明显的边缘进一步钝化,最后效果如下:

可以看到右边的图像明显比昨天的模糊,而且白色区域变得更大,边缘过渡更加自然。
总结
这次图像的 3d 化涉及到的内容实在太多了,从原本效果最好的 3D-Photo-Inpainting,结果运行速度实在太慢,优化 python 代码后也要 2min,于是参考 2015 年的项目 depthy。用 MiDaS 生成景深图,并通过 FastAPI 返回数据。迁移部分 angular2 代码到现在的 vue3 项目。web 端最后要修改 PixiJS 里面的 webgl 渲染方式,并用 opencv 来优化景深图像,达到基本可用效果。不过整体回顾下来还是一次非常有趣的经历。