A gym environment for the Lucky World simulator
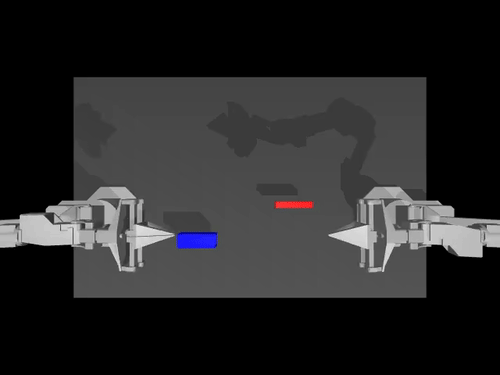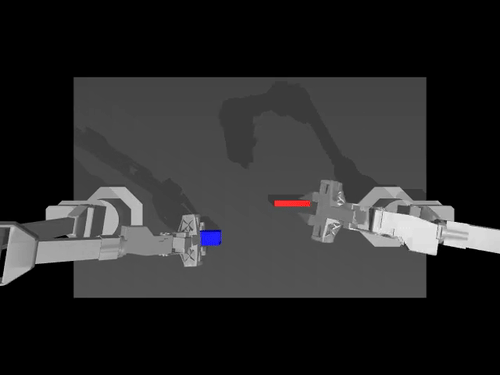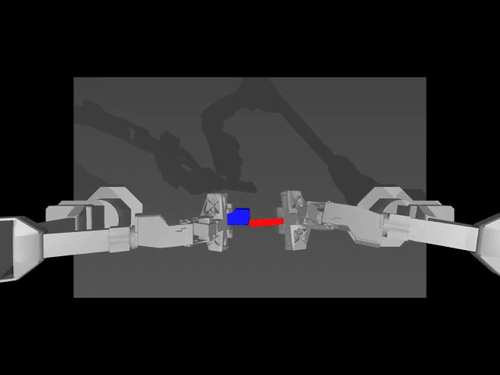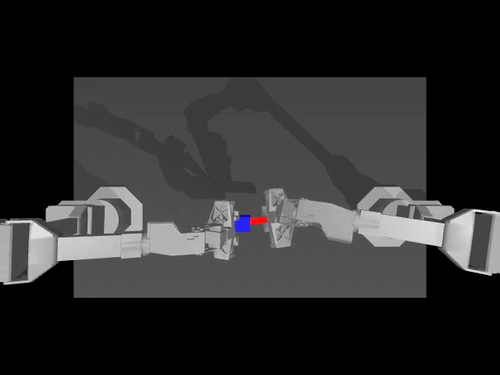
Create a virtual environment with Python 3.13 and activate it, e.g. with miniconda:
conda create -y -n luckyworld python=3.13 && conda activate luckyworldInstall gym-luckyworld:
pip install gym-luckyworldimport imageio
import numpy as np
import gymnasium as gym
import gym_luckyworld # noqa: F401
env = gym.make("gym_luckyworld/LuckyWorld-PickandPlace-v0")
observation, info = env.reset()
frames = []
for _ in range(1000):
action = env.action_space.sample()
observation, reward, terminated, truncated, info = env.step(action)
image = env.render()
if env.render_mode == "rgb_array":
frames.append(image)
if terminated or truncated:
observation, info = env.reset()
env.close()
if env.render_mode == "rgb_array":
imageio.mimsave("example.mp4", np.stack(frames), fps=10)LuckyWorld environment for imitation learning with robotic manipulation tasks.
Two tasks are available:
- PickandPlace: The SO100 robot arm needs to pick up objects and place them at target locations.
- Navigation: Robot navigation tasks for mobile platforms.
- SO100: 6-DOF robotic arm with the following actuators:
shoulder_pan: Shoulder rotation (-2.2 to 2.2 rad)shoulder_lift: Shoulder elevation (-3.14 to 0.2 rad)elbow_flex: Elbow joint (0.0 to 3.14 rad)wrist_flex: Wrist flexion (-2.0 to 1.8 rad)wrist_roll: Wrist rotation (-3.14 to 3.14 rad)gripper: Gripper position (-0.2 to 2.0)
The action space consists of continuous values for the robot's joint positions, resulting in a 6-dimensional vector for SO100:
- Six values for the arm's joint positions (absolute values within joint limits).
Observations are provided as a dictionary with the following keys:
agent_pos: Current joint positions of the robot arm (6D vector for SO100).pixels: RGB camera feed (480x640x3) from the robot's perspective.
Important: This environment is designed for imitation learning. All rewards are set to 0.0 by default.
For reinforcement learning applications, you must implement custom reward functions by:
- Subclassing the task classes (
PickandPlace,Navigation) - Overriding the
get_reward()method with your domain-specific reward logic
Episodes terminate based on task-specific conditions:
- PickandPlace:
- Success: Object is placed at target location
- Failure: Object is dropped away from target
- Navigation:
- Success: Robot reaches target location
- Failure: Robot collides with obstacles
The robot and environment objects start at randomized positions within predefined bounds.
>>> import gymnasium as gym
>>> import gym_luckyworld
>>> env = gym.make("gym_luckyworld/LuckyWorld-PickandPlace-v0", obs_type="pixels_agent_pos", render_mode="rgb_array")
>>> env
<TimeLimit<OrderEnforcing<PassiveEnvChecker<LuckyWorldEnv<gym_luckyworld/LuckyWorld-PickandPlace-v0>>>>>obs_type: (str) The observation type. Currently supportspixels_agent_pos(camera + joint positions). Default ispixels_agent_pos.render_mode: (str) The rendering mode. Can behuman(OpenCV windows) orrgb_array(numpy arrays). Default ishuman.scene: (str) The scene to load. Default iskitchen.robot_type: (str) The robot type. Currently supportsso100. Default isso100.timeout: (float) Maximum episode duration in seconds. Default is30.0.
import gymnasium as gym
import gym_luckyworld
# Create environment
env = gym.make(
"gym_luckyworld/LuckyWorld-PickandPlace-v0",
obs_type="pixels_agent_pos",
render_mode="rgb_array"
)
# Collect demonstration data
observations = []
actions = []
obs, info = env.reset()
for step in range(100):
# Your demonstration policy here
action = your_policy(obs)
observations.append(obs)
actions.append(action)
obs, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
obs, info = env.reset()
env.close()
# Use observations and actions for imitation learning
# (e.g., with ACT, BC, IQL, etc.)If you want to use this environment for reinforcement learning, implement custom rewards:
from gym_luckyworld.task import PickandPlace
class RewardedPickandPlace(PickandPlace):
def get_reward(self, observation, info):
# Implement your reward logic here
object_distance = info.get("object_distance_from_target", float('inf'))
reward = -object_distance # Negative distance as reward
# Add success bonus
if object_distance < self.distance_threshold:
reward += 100.0
return reward
# Use your custom task
env = gym.make("gym_luckyworld/LuckyWorld-PickandPlace-v0")
env.task = RewardedPickandPlace("kitchen", "pickandplace", "so100", "human")Instead of using pip directly, we use poetry for development purposes to easily track our dependencies.
If you don't have it already, follow the instructions to install it.
Install the project with dev dependencies:
poetry install --all-extras# install pre-commit hooks
pre-commit install
# apply style and linter checks on staged files
pre-commitgym-luckyworld is adapted from gym-aloha and built on top of the LuckyRobots simulation platform.