fix: stabilize & improve the FUSE layer #49
Comments
|
I recall why I made a memory buffer per file. As an app writes to a file, even a small chunk, it had to go through encryption of the full file at the overlay layer. More importantly it disconnect the old node (with previous version) and make it efficiently ghost. So not having a buffer was difficult due to the overhead of staging it to the git. |
|
Okay, thanks. Design-wise it actually should only do that when the file is closed or flushed. So maybe there is a bug that causes a flush on every write. Or do you mean that? |
|
Just a FYI, found a picture from my master thesis that might help explain how the |
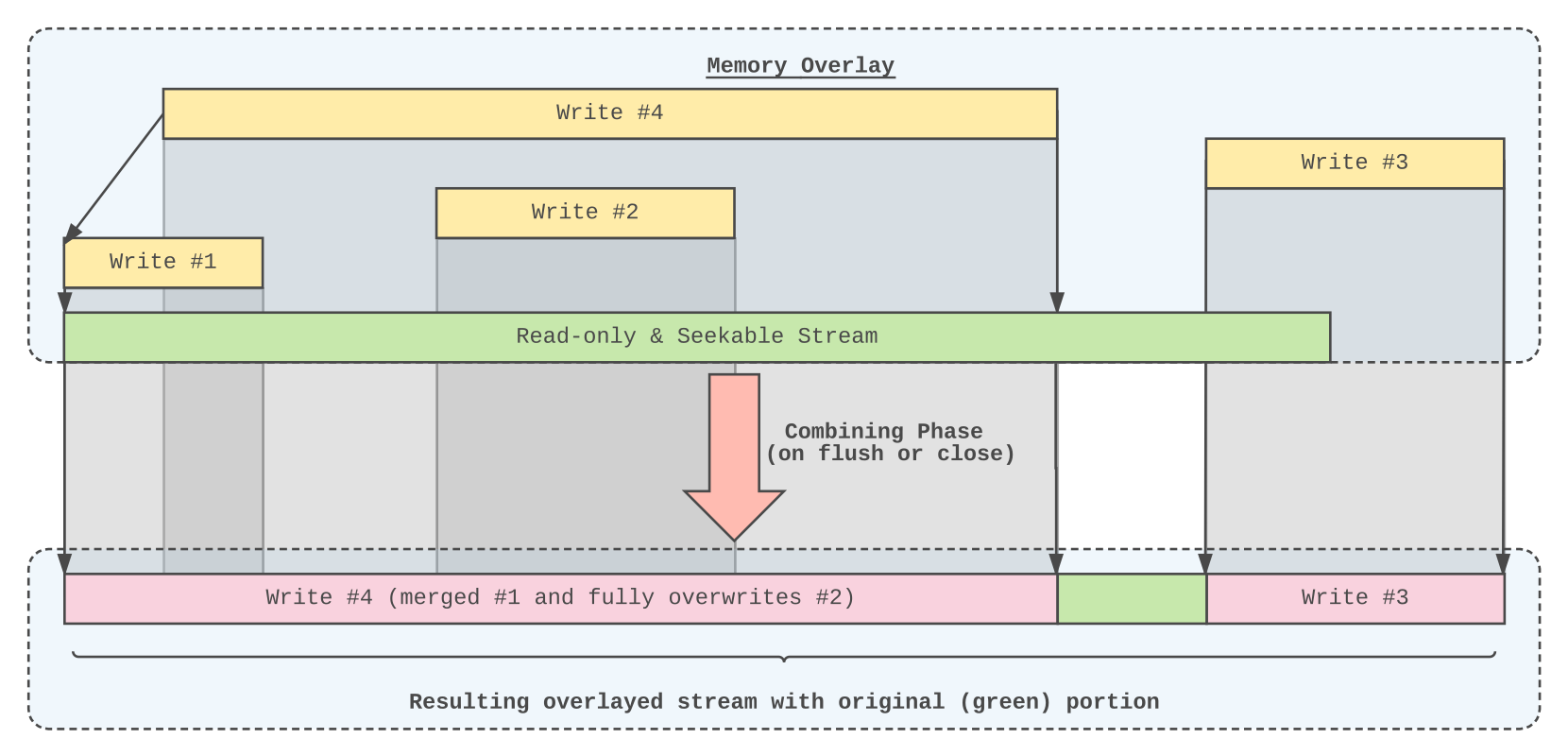
|
I had this write-up now lying around a few days and forgot to update it, so I figured I better post it. Some parts of it are rather rough, but usually one figures out the missing parts while going. ProposalSummary: Current implementation holds a buffer per file (if opened rw) with all its Current statePer the changes of @evgmik we keep a file handle with the complete buffer of the file Desired stateWe want to have the following properties for the FUSE filesystem:
This is basically what file systems in the kernel would do and since we're doing it in userspace RoadmapThe change can be carried out in smaller iterations, each of them a little Bring back overlayIt is currently short circuited. Measure performance as baseline before and Lower amounts of SeeksEvery FUSE read and write currently does a Seek to ensure it is in the right place. Change encryption streamProbably back to random keys. This would eliminate the need to read each staged stream twice. Make overlay use badger to store writesIdeally the overlay system Keep LRU read cache in overlayWe could think of a scheme to keep often read pages in the memory of a LRU cache. Block based storageProbably most controversial one, but also the one that will get the most out of Sequential write detectionWhen copying a file into FUSE (either as new file or as an existing one) we can I will write issue tickets for each of those while going on. |
|
@evgmik: I see you assigned yourself to this ticket. What's the current state? |
|
I am working (meaning thinking and investigating the code) to work on
in the context "would it give faster performance?". In the same context, I am looking where is the bottle neck between I am reluctant to go to Somewhat irrelevant to |
I would guess seeking in the stream & too many copying between buffers? Seeking is highly expensive - also because You could also benchmark reading a file sequentially without calling Seek() (other cases would break obviously) and compare that to the memory buffer. If that's lots faster, seek is to blame. Another test could be to read the file from But that's just a guess from my side and where my gut feeling would get me first...
I would assume that kernel does not cache anything going over FUSE, since every call to read, write etc. will execute code that might yield another result every time. If there's no way to tell the kernel which pages are safe to cache it would not be safe to do. I would assume that it's filesystem's duty to implement that. But I would be happy to be wrong. Maybe that helps, but I guess you don't have a open/close in between. By the way, how did you check this is the case? Side note, I discovered last time that you can pass a debug logger here when passing a config instead of nil to
Good question and as usual I don't remember. I remember darkly that it was very dependent on the machine (depending on CPU) and that sometimes AES was actually faster. But that situation might have changed, so it's worth to re-evaluate. I would be fine to switch to ChaCha20.
That would be my next task. Implementing the hints system to tell EDIT: Nice introductionary paper: https://www.fsl.cs.stonybrook.edu/docs/fuse/fuse-tos19-a15-vangoor.pdf |
I did my test with continuous Line 90 in add2749 Also, I did some test by disabling encryption layer, or even switching encryption to
I discovered this little gem too. Enabling
If I call With
Have not noticed it, thanks.
You commit has "Better safe than sorry" when you switched to AES. Some modern hardware apparently has AES hardware implementation, but on my 10 year old AMD Phenom it apparently not implemented, so it is slow and very CPU demanding.
Cool. Than I will not mess with it. I would say a line in config would be good, or maybe a switch too. I was also thinking how to implement |
Then that benchmark really seems to be suspicious... 😏
There is the write-back cache, as described in this paper.
Nice. Having those benchmark results reproducible would be important.,
Ah, I did not realize I made such a comment in the commit. 🙈 Sadly it's an example of a bad commit message since I don't really know what my motivations where back then. From my writing it sounds like it's also a security related thing, but I need to research it.
That would actually speak for keeping AES. Modern CPUs (including the Intel i7-7500U in my laptop) have the AES-NI. Guess we need to benchmark things and maybe also research implementations.
We should have this info before we start reading. I detailed the approach here. |
|
I am reworking fuse to work directly with Line 97 in 1c9f62c ipfs but I cannot getwhere is it happening. I disable everything below line Line 122 in 1c9f62c it still doing something with ipfs. Can you point me to the place where it is happening? Because performanceof this Write is pitiful (200 kB/s) when overwriting. (Write to new file is very fast)
I do not understand why we talk to P.S. short status report. Enabling Now I am trying to make above parts work fast enough. |
I would need to look more into this, but does this happen already on Write or bit later on Flush? On the latter we stage the file by using the Other than that it might be another go routine doing something. How do you check if we're talking to IPFS?
Nice! |
Took me a while, some how |
|
Re-opening, since that ticket has more stuff to do (e.g. overlay page swapping). I was curious and checked what you reported earlier. Repository file size is indeed increasing fast on every write (about 4K). That's a lot, but less than before the recent fuse changes (where each individual write causes a metadata write). The test was done like this: $ ./scripts/test-bed.sh -s
$ ali mount /tmp/blah
$ for i in $(seq 0 100); do dd if=/dev/urandom of=/tmp/blah/file bs=1M count=2 status=none; du -hs /tmp/ali; doneI checked the repository and almost all (unsurprisingly) is used by the metadata directory. I checked with badger-cli and the biggest chunk happens during pinning. For reference, here are the keys with their size: What's noticeable is that we have more pin entries than ha 8000 shes. Also each pin entry is pretty large (almost as much as a metadata entry, and those have to store way more data). I would have expected it to allocate a few bytes, since it just stores a few inodes and a bool. Want to have a look @evgmik, dig a bit deeper and write a ticket? EDIT: Also noticed the key numbers do not add up to the size of the database on the filesystem. It was around 600k in my case, numbers only add up to around 50k 🤔 |
|
I was curious and checked what you reported earlier. Repository file size is indeed increasing fast on every write (about 4K). That's a lot, but less than before the recent fuse changes (where each individual write causes a metadata write). The test was done like this:
I will look at it, the
Could you elaborate what do you mean by "the key numbers"? |
By key numbers I meant the size numbers behind each key. Those do not add up to the expected size. |
|
The whole thing is very weird.
I am still digging, but it all make very little sense. As well as, why the badger db takes so much space even at fresh init. By the way we are using badger v1.6.2, while upstream moved to v3.2011.1. Maybe they fixed some bugs. |
|
It seems that But badger db does something else, and eats even more space. A simple |
Agreed. I wonder what happens if we'd not set all keys on top-level (joined with a dotted path)
Yes, I think updating badger is a good idea. Updating might be a little rough, due to minor API breakage, but should be doable. |
|
There is a bug in Second is not a bug, but the use The fixes are in my Why the |
As I reported earlier As to the question why we have more pins than hashes. The answer is in the linker logic as well as repinner. Repinner will delete everything beyond default 10 versions, but badger So this is not We can make new fuse unrelated issue from it. But it all indicates a need to do hints for pins before we do major logic change. |
I am not sure that I follow. Do you think that '.' dot is somehow special from the |
No, no dot is not special. But other key-value stores support the concept of buckets, where you can nest keys into each other. I forgot that badger does not even support that, so please ignore my comment regarding that. 😄
Yes, let's wait for the re-design of the pin feature to tackle this anyways.
Yep, this is an oversight and should be corrected on redesign. Thanks for the investigation work. |
|
FYI: Next task on my list is implementing swapping support for overlay. This is also the last bigger item for 0.6.0, beside writing some better integration tests. Once done we just need to tune and proof-read the documentation a bit and have the first proper release since years. 🎉 |
|
Sounds good. We should also do some stress testing of sync on somewhat life scenarios. We pass the tests, but I am not sure, we covered all possible permutations move, delete, modify, add, etc. I fire up |
|
Just as a heads up, I'm still working on the new overlay. Thought up a concept that works nicely (or so I hope) with both in-memory and on-disk caching. New implementation will be larger, but hopefully also easier to understand as concept and more efficient. I hope I can get it working until next weekend. |
|
Thanks for update. Looking forward to test it. I just put |
I don't think that (pure write case) is getting much better with the new approach - if at all. If you add many files, adding them over |
|
Here the short update on benchmark. This time I did it on my laptop with a solid state drive and a bit more powerful CPU.
Overall So we are loosing our transfer rate somewhere else. Is it due to reconnection to IPFS or something else, and why |
Good question. My shallow guess: There is likely some gap in between files. Also
Needs some more debugging, I guess. |
|
Page cache is now implemented as of #104. I vote for closing this ticket and opening another, more specialized one if the performance problems described in the last few posts persist. Original post also talked about about block-level optimization, but I do consider those out of scope for now. I will keep it in the back of my head though. |
Things that should be tackled:
catfs/mio/overlay) should be partly reverted.(Note: The above could be implemented by using BadgerDB instead of keeping modifications in memory)
Other things:
The text was updated successfully, but these errors were encountered: