LLM-Augmented Multi-Agent System (MAS) for Automated Claim Extraction, Evidential Verification, and Fact Resolution
Hey there! I've been working on this fact-checking system for a while, and I'm pretty excited to share it. What we've got here is a comprehensive LangGraph implementation that helps you verify the factual accuracy of text. It'll break down a text into individual claims, check each one against real-world evidence, and then give you a detailed report on what's accurate and what's not.
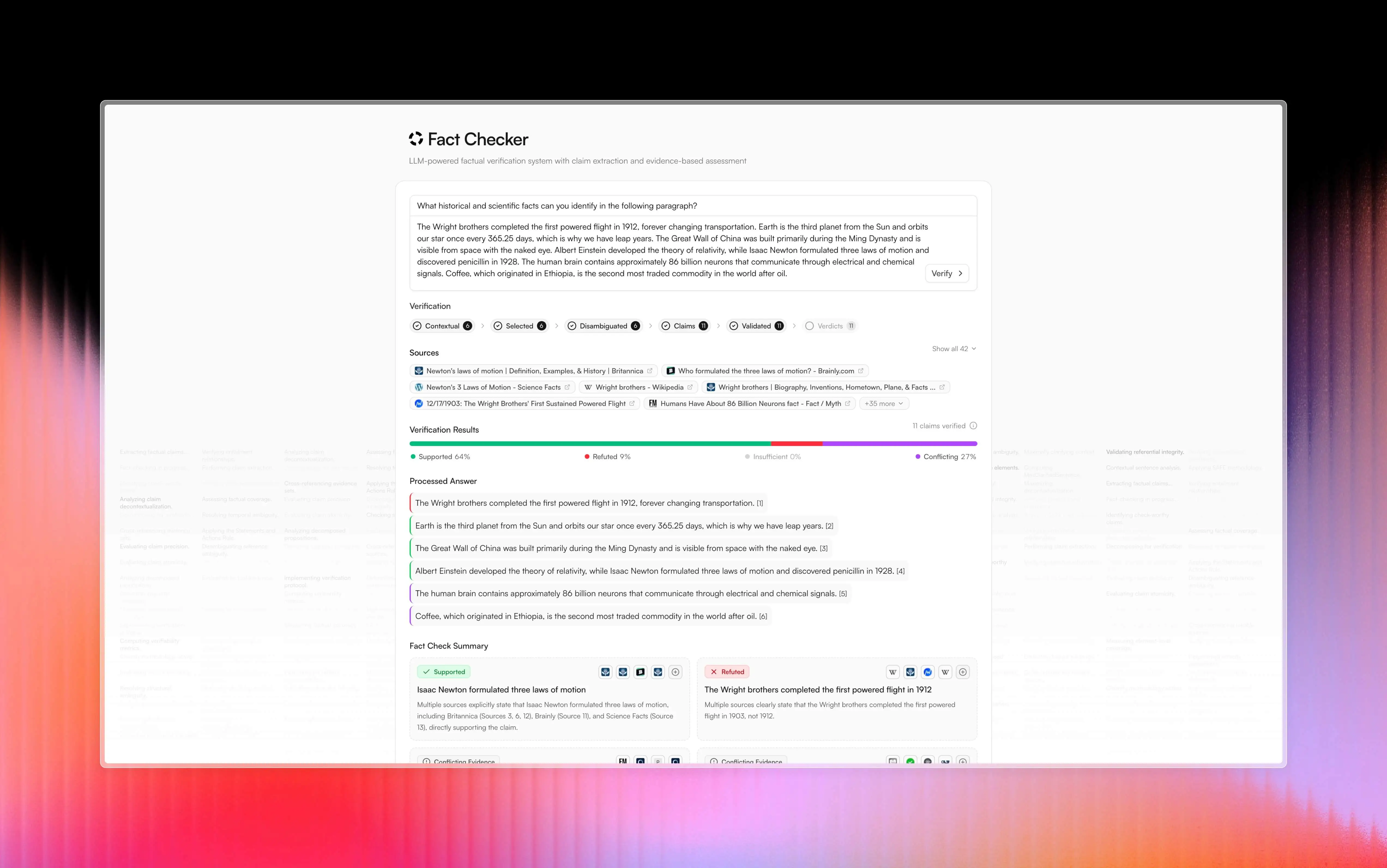
The system is split into three main parts (I found this modular approach works way better than a single monolithic system):
- Claim Extractor (
claim_extractor/): Pulls out factual claims from text using the Claimify methodology. - Claim Verifier (
claim_verifier/): Checks each claim against online evidence through Tavily Search. - Fact Checker (
fact_checker/): Ties everything together and generates the final report.
Let's face it - content from LLMs (or humans!) can sometimes include statements that aren't quite right. I wanted to build a system that could help identify what's factually solid and what might need a second look.
Here's how it works in practice:
- You feed in a question and its answer (or any text you want to fact-check).
- The Claim Extractor breaks it down into specific, testable claims. This part was tricky to get right - we needed to handle pronouns, context, and ambiguity. Check out
claim_extractor/README.mdif you're curious about the details. - The Claim Verifier then takes each claim and tries to verify it. It'll search the web, gather evidence, and decide if the claim is supported, refuted, or if there's just not enough information. There's a lot of nuance here - sometimes the evidence is conflicting!
- Finally, you get a comprehensive report showing which claims held up and which didn't. I've found this breakdown approach much more useful than a simple "true/false" on the entire text.
The system runs on LangGraph for orchestrating the workflows. Here's how the pieces connect:
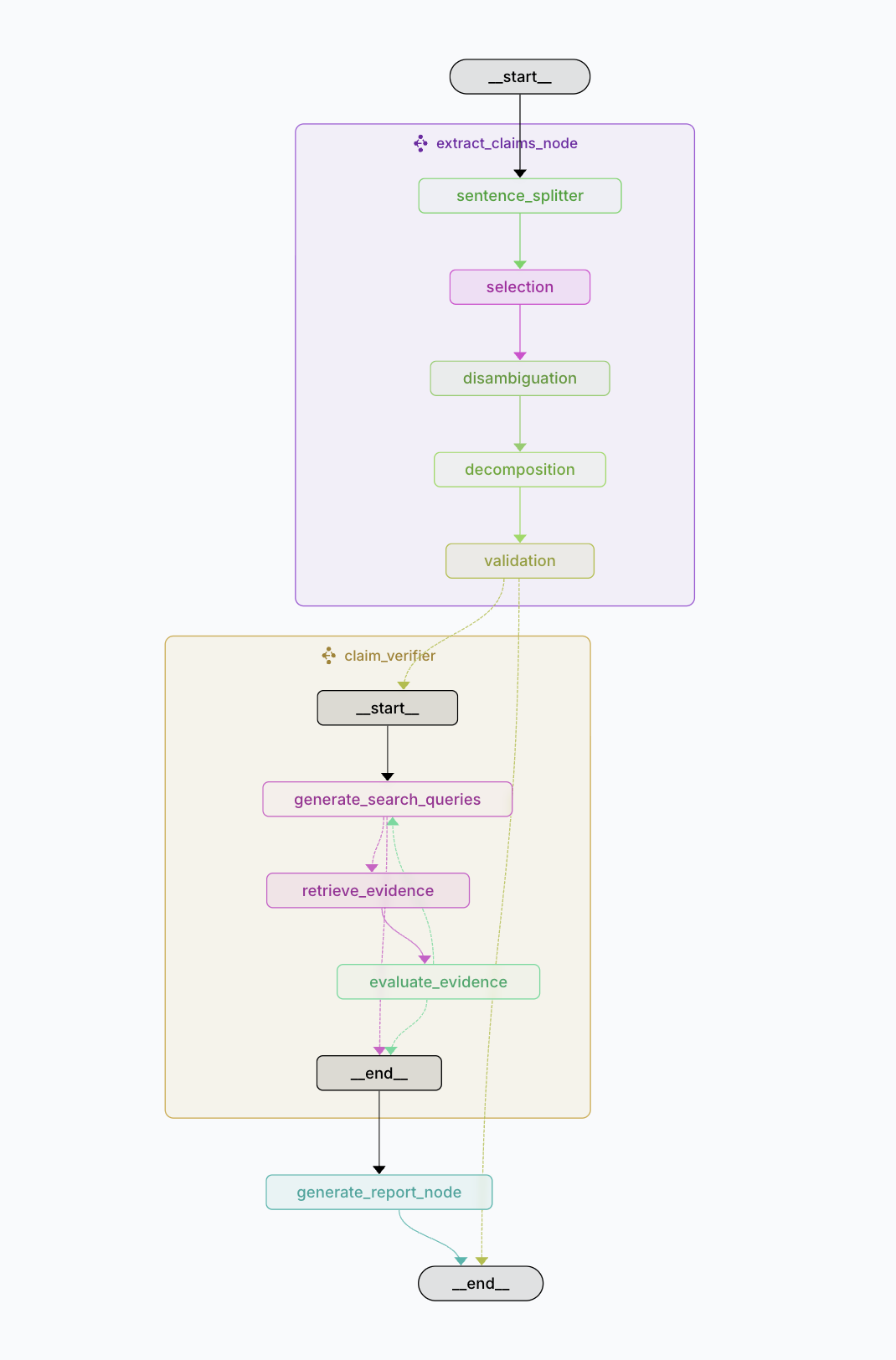
It's a bit complex, I know! I spent way too much time getting these interactions right. If you want to understand a specific part better, check out the detailed READMEs:
- Claim Extractor README - The nitty-gritty on how we extract claims
- Claim Verifier README - How we verify claims against real-world evidence
- Fact Checker README - How we orchestrate everything
Each component has its own configuration options in their config/ folders. I've spent a lot of time fine-tuning these settings, but you might want to adjust them for your specific needs:
- Temperature settings for LLM calls (how creative vs. deterministic you want things)
- Number of web search results to collect
- Retry attempts for ambiguous claims
- and much more...
The module READMEs have detailed info on what you can customize.
The claim_extractor is built on the Claimify methodology from Metropolitansky & Larson's 2025 paper. It's pretty fascinating stuff - they figured out how to handle ambiguity and extract verifiable claims. I spent a good week just implementing their pipeline, and it was worth it. The full citation and details are in the claim_extractor/README.md.
For the claim_verifier, the evidence retrieval approach draws some inspiration from the Search-Augmented Factuality Evaluator (SAFE) methodology in "Long-form factuality in large language models" by Wei et al. (2024). Just the basic idea of using search results to verify individual claims.
Look, I've tried my best to faithfully implement everything described in the research papers, especially Claimify. But let's be real - there's always room for improvement and I might have missed some minor details along the way. I also took some creative liberties to enhance what was in the papers, adding features like the voting mechanism for disambiguation and the multi-retry approach for verification.
What you're seeing here is my interpretation of these research methods, with some practical additions that I found helpful when implementing in the real world. If you spot something that doesn't align perfectly with the papers, that's probably intentional - I was aiming for a working system that captured the spirit of the research while being practically useful.
The beauty of building on research is that we get to stand on the shoulders of giants AND add our own twist. I believe this implementation represents the core ideas faithfully while adding practical enhancements that make it even more effective.
For detailed installation instructions, see INSTALLATION.md
Quick start:
git clone https://github.com/bharathxd/fact-checker.git
cd fact-checker
pnpm setup:dev
pnpm devfact-checker/
├── .langgraph_api/ # LangGraph API configuration
├── apps/
│ ├── fact-checker/ # Core fact-checking modules
│ │ ├── claim_extractor/ # Extracts claims from text
│ │ ├── claim_verifier/ # Verifies extracted claims
│ │ ├── fact_checker/ # Orchestrates the fact-checking process
│ │ └── utils/ # Shared utilities
│ └── web/ # Web interface
│ ├── public/ # Static assets
│ └── src/ # Frontend React/Next.js code
├── packages/ # Shared packages
└── scripts/ # Utility scripts
For detailed documentation on each component, refer to their respective README files:
This project wouldn't have been possible without:
- Dasha Metropolitansky & Jonathan Larson from Microsoft Research - their Claimify methodology is brilliant
- Jerry Wei and team at Google DeepMind - their SAFE paper had some useful ideas for evidence retrieval
- The LangChain team - LangGraph made the complex workflows so much easier
- OpenAI - for the LLMs that power the text understanding
- Tavily AI - their search API is perfect for this use case
I've learned a ton working on this project. If you use it or have ideas for improvements, I'd love to hear about it! Contributions are always welcome - whether it's code, suggestions, or even just sharing how you're using it. Let's make this thing even better together.
Here's what's coming next for the Fact Checker system:
-
Add an evaluation agent - Create a dedicated component to assess the overall performance of the fact-checking process and provide metrics on accuracy and reliability.
-
Create a public facing API (as a service) - Develop and deploy a robust API service that allows external applications to leverage the fact-checking capabilities without needing to run the full system locally.
Contributions are welcome! Here's how you can help:
- Fork the repository
- Create a feature branch:
git checkout -b feature/amazing-feature - Commit your changes:
git commit -m 'Add some amazing feature' - Push to the branch:
git push origin feature/amazing-feature - Open a Pull Request
Before submitting your PR, please:
- Make sure your code follows the existing style
- Add/update tests as necessary
- Update documentation to reflect your changes
- Ensure all tests pass
This project is licensed under the MIT License - see the LICENSE file for details.
- Issues: Please use the GitHub Issue Tracker to report bugs or request features
- Email: bharathxxd@gmail.com
- Twitter: @Bharath_uwu