


Blackdagger is a powerful, user-friendly framework designed to orchestrate complex workflows in DevOps, DevSecOps, MLOps, MLSecOps, and Continuous Automated Red Teaming (CART) environments. By leveraging a declarative YAML format and a Directed Acyclic Graph (DAG) structure, Blackdagger simplifies the definition, management, and execution of automation pipelines, enabling seamless integration with containerized environments and versatile task execution.
- Declarative YAML Format: Blackdagger uses a YAML-based DAG to define workflows, simplifying complex task dependencies without the need for scripting.
- Web UI for Visual Management: Intuitive browser interface for managing, monitoring, and rerunning pipelines with real-time status and logs.
- Native Docker Support: Seamlessly integrates Docker containers for efficient task orchestration in distributed environments.
- Versatile Task Execution: Supports HTTP requests, SSH commands, and custom code for flexible automation.
You can find everything about Blackdagger, including this README, in our documentation.
- Key Features
- Evolution of Blackdagger to a Framework
- Installation
- Quick Start Guide
- CLI
- Web UI
- Documentation
- Use cases
- Example Workflow
- Tutorial Videos
- Motivation
- Why Not Use an Existing Workflow Scheduler Like Airflow?
- How It Works
- Roadmap
- License
- Web UI & CLI for managing and executing DAGs
- YAML-based DAG definition, supporting:
- Custom code execution
- Parameters, command substitution, and conditional logic
- Output redirection (stdout/stderr)
- Lifecycle hooks and task repetition
- Automatic retries
- Executors for:
- Running Docker containers
- Making HTTP requests
- Sending emails
- Running jq command
- Executing remote commands via SSH
- Email notifications
- Scheduling with Cron expressions
- REST API
- Basic Authentication over HTTPS
To improve usability and streamline complex workflows, the team introduced a structured framework around Blackdagger. This includes pre-configured YAML files for common use cases and deployable infrastructure for Continuous Automated Red Teaming (CART) and DevSecOps. These additions are consolidated under the Blackdagger: Cyber Workflow Automation Framework, providing a cohesive solution that enhances the tool's overall effectiveness.
The framework consists of 5 components:
- Blackdagger (this repository): Core of the framework for orchestrating the components and workflows
- Blackcart: A specialized Docker image optimized for Continuous Automated Red Teaming (CART) and DevSecOps pipeline tasks.
- Blackdagger YAMLs: Pre-tested example workflows, demonstrating real-world DevSecOps and CART use-cases, facilitating quick adoption and adaptation.
- Blackdagger Github Infra: A suite of advanced workflows utilizing GitHub Actions infrastructure for enhanced defense evasion techniques, scalability, and performance.
- Blackdagger Web Kit: A browser extension integrating core functionalities, allowing direct execution of Blackdagger workflows from the browser.
Each component within the framework is designed for interoperability, allowing seamless integration across various environments and use cases with maximum ease, speed, and efficiency. The framework is modular, supporting the addition, removal, or modification of components to introduce new features or adapt to evolving requirements.
With Blackdagger at its core, this repository offers a detailed overview of the framework's capabilities. For more information on specific components, please refer to their individual repositories.
- A Linux, macOS, or Windows system with bash or Docker installed.
- For certain workflows,
sudopermissions may be required (see Sudo Configuration).
# Step 1: Download the script
curl -L https://raw.githubusercontent.com/ErdemOzgen/blackdagger/main/scripts/blackdagger-installer.sh -o blackdagger-installer.sh
# Step 2: Make the script executable if needed
chmod +x blackdagger-installer.sh
# Step 3: Run the script with sudo
sudo bash blackdagger-installer.sh
Important Note: Within the Blackdagger server, to access the GoTTY web terminal, you must manually start the default-gotty-service DAG found in the DAGs section. Blackdagger utilizes GoTTY for web terminal functionality, which, for security reasons, does not automatically start upon system initialization.
# Clone the repository and run Docker Compose
git clone https://github.com/ErdemOzgen/blackdagger.git
cd blackdagger
docker compose up
# If docker compose does not work please try to docker compose build
#docker compose buildAccess the Web UI at http://127.0.0.1:8080 and the GoTTY web terminal at http://127.0.0.1:8090 (username: blackdagger, password: blackdagger) (Do not forget to run default-gotty-service dag at http://[::]:8080/dags/default-gotty-service).
Download the latest binary from the Releases page and place it in your $PATH (e.g. /usr/bin).
Some YAML configurations or processes executed through Blackdagger may require sudo permissions. To ensure smooth operation, users should configure the necessary sudo access beforehand. Without it, core functionalities such as running, maintaining, or stopping processes—as well as other Blackdagger features—may not function correctly or could result in errors. Below are several options for configuring sudo permissions:
- First and suggested option is adding user account to the /etc/sudoers file with NOPASSWD permissions, enabling them to execute sudo commands without needing to enter a password. This modification simplifies operations that require elevated privileges by removing the requirement to provide a password for each sudo command.
In the terminal, type the following command to open the sudoers file using a text editor:
sudo visudo -f /etc/sudoersScroll down to the bottom of the sudoers file. Add the following line, replacing "username" with the actual username of the user account you want to grant sudo privileges without a password:
username ALL=(ALL) NOPASSWD: ALLSave your changes and exit the editor.
- To have root privileges you can run Blackdagger with sudo:
sudo blackdagger start-allBut this will create Blackdagger-related folders in root user. It may cause python package issues and pip related problems.
- To ensure continuous operation of the process on your system, simply create and execute the following script every minute via cron—no root account required:
#!/bin/bash
process="blackdagger start-all"
command="/usr/bin/blackdagger start-all"
if ps ax | grep -v grep | grep "$process" > /dev/null
then
exit
else
$command &
fi
exitAfter installation, you can use the provided YAML files, which were created to support a variety of use cases. These examples demonstrate the mechanisms available in Blackdagger and are intended to guide and inspire you in creating your own YAML configurations or adapting the existing ones to fit your specific needs.
For now, we have these categories of YAMLs:
- Default: Default YAMLs that consist of general mechanisms that you can use in any YAML file, such as parallel job running and conditional mechanisms.
- DevSecOps: YAMLs that will help you to setup an environment and install common tools for DevSecOps, along with language specific YAML files that you can use to run DevSecOps processes on your projects.
- CART: YAMLs that will help you to prepare, plan and perform CART processes. We advise you to use these YAMLs in Blackcart since there is a pre-configured environment and a whole arsenal for CART purposes.
- DevOps: TBU
- MLOps: TBU
- MLSecOps: TBU
After installing Blackdagger, you can download these YAMLs by their categories by running the command:
# Categories: mlops, default, devsecops, devops, mlsecops, cart
blackdagger pull <category>This command pulls YAML files from the repositories listed above. Each file follows the Blackdagger YAML format and is designed for a variety of common use cases. They have been thoroughly tested to provide a reliable and efficient way to execute your desired actions quickly.
Start the server and scheduler with the command blackdagger start-all or blackdagger server and browse to http://127.0.0.1:8080 to explore the Web UI.
Navigate to the DAG List page by clicking the menu in the left panel of the Web UI. Then create a DAG by clicking the New button at the top of the page. Enter example in the dialog.
Note: DAG (YAML) files will be placed in ~/.config/blackdagger/dags by default. See Configuration Options for more details.
Go to the SPEC Tab and hit the Edit button. Copy & Paste the following example and click the Save button.
Example:
schedule: "* * * * *" # Run the DAG every minute
steps:
- name: s1
command: echo Hello blackdagger
- name: s2
command: echo done!
depends:
- s1You can execute the example by pressing the Start button. You can see "Hello blackdagger" in the log page in the Web UI.
The following commands are available for interacting with Blackdagger:
# Runs the DAG
blackdagger start [--params=<params>] <file>
# Displays the current status of the DAG
blackdagger status <file>
# Re-runs the specified DAG run
blackdagger retry --req=<request-id> <file>
# Stops the DAG execution
blackdagger stop <file>
# Restarts the current running DAG
blackdagger restart <file>
# Dry-runs the DAG
blackdagger dry [--params=<params>] <file>
# Launches both the web UI server and scheduler process
blackdagger start-all [--host=<host>] [--port=<port>] [--dags=<path to directory>]
# Launches the blackdagger web UI server
blackdagger server [--host=<host>] [--port=<port>] [--dags=<path to directory>]
# Starts the scheduler process
blackdagger scheduler [--dags=<path to directory>]
# Pulls the latest version of DAGs from the specified category or an origin repository.
blackdagger pull [category] [--origin] [--check] [--keep]
# Shows the current binary version
blackdagger versionMain index page of blackdagger. It shows dag status and timeline for all dags.
It shows all DAGs and the real-time status.
It shows the real-time status, logs, and DAG configurations. You can edit DAG configurations on a browser. You can switch to the vertical graph with the button on the top right corner.
Provides detailed specifications of a DAG, including editable steps, conditions, parameters, and preconditions to define the workflow logic.
It shows past execution results and logs.
It shows the detail log and standard output of each execution and step.
It greps given text across all DAGs.
- Installation Instructions
- ️Quick Start Guide
- Command Line Interface
- Web User Interface
- YAML Format
- Minimal DAG Definition
- Running Arbitrary Code Snippets
- Defining Environment Variables
- Defining and Using Parameters
- Using Command Substitution
- Adding Conditional Logic
- Setting Environment Variables with Standard Output
- Redirecting Stdout and Stderr
- Adding Lifecycle Hooks
- Repeating a Task at Regular Intervals
- All Available Fields for DAGs
- All Available Fields for Steps
- Example DAGs
- Configurations
- Scheduler
- Docker Compose
- REST API Documentation
- Data Pipeline Automation: Schedule ETL tasks to process and centralize data.
- Infrastructure Monitoring: Periodically check infrastructure components with HTTP requests or SSH commands.
- Automated Reporting: Generate and send periodic reports via email.
- Batch Processing: Schedule batch jobs for tasks like data cleansing or model training.
- Task Dependency Management: Manage complex workflows with interdependent tasks.
- Microservices Orchestration: Define and manage dependencies between microservices.
- CI/CD Integration: Automate code deployment, testing, and environment updates.
- Alerting System: Create notifications based on specific triggers or conditions.
- Custom Task Automation: Define and schedule custom tasks using code snippets.
- Model Training Automation: Automate the training of machine learning models by scheduling jobs that run on new data sets. Use Blackdagger to manage dependencies between data preprocessing, training, evaluation, and deployment tasks.
- Model Deployment Pipeline: Create a DAG to automate the deployment of trained models to production environments, including steps for model validation, containerization with Docker, and deployment using SSH commands.
- Security Scans Integration: Schedule regular security scans and static code analysis as part of the CI/CD pipeline. Use Blackdagger to orchestrate these tasks, ensuring that deployments are halted if vulnerabilities are detected.
- Automated Compliance Checks: Set up workflows to automatically run compliance checks against infrastructure and codebase, reporting results via HTTP requests to compliance monitoring tools.
- Automated Penetration Testing: Schedule and manage continuous penetration testing activities. Define dependencies in Blackdagger to ensure that penetration tests are conducted after deployment but before wide release, using Docker containers to isolate testing environments.
- Threat Simulation and Response: Automate the execution of threat simulations to test the effectiveness of security measures. Use Blackdagger to orchestrate complex scenarios involving multiple steps, such as breaching a system, escalating privileges, and exfiltrating data, followed by automated rollback and alerting.
This example workflow showcases a data pipeline typically implemented in DevOps and Data Engineering scenarios. It demonstrates an end-to-end data processing cycle starting from data acquisition and cleansing to transformation, loading, analysis, reporting, and ultimately, cleanup.
The YAML code below represents this workflow:
# Environment variables used throughout the pipeline
env:
- DATA_DIR: /data
- SCRIPT_DIR: /scripts
- LOG_DIR: /log
# ... other variables can be added here
# Handlers to manage errors and cleanup after execution
handlerOn:
failure:
command: "echo error"
exit:
command: "echo clean up"
# The schedule for the workflow execution in cron format
# This schedule runs the workflow daily at 12:00 AM
schedule: "0 0 * * *"
steps:
# Step 1: Pull the latest data from a data source
- name: pull_data
command: "bash"
script: |
echo `date '+%Y-%m-%d'`
output: DATE
# Step 2: Cleanse and prepare the data
- name: cleanse_data
command: echo cleansing ${DATA_DIR}/${DATE}.csv
depends:
- pull_data
# Step 3: Transform the data
- name: transform_data
command: echo transforming ${DATA_DIR}/${DATE}_clean.csv
depends:
- cleanse_data
# Parallel Step 1: Load the data into a database
- name: load_data
command: echo loading ${DATA_DIR}/${DATE}_transformed.csv
depends:
- transform_data
# Parallel Step 2: Generate a statistical report
- name: generate_report
command: echo generating report ${DATA_DIR}/${DATE}_transformed.csv
depends:
- transform_data
# Step 4: Run some analytics
- name: run_analytics
command: echo running analytics ${DATA_DIR}/${DATE}_transformed.csv
depends:
- load_data
# Step 5: Send an email report
- name: send_report
command: echo sending email ${DATA_DIR}/${DATE}_analytics.csv
depends:
- run_analytics
- generate_report
# Step 6: Cleanup temporary files
- name: cleanup
command: echo removing ${DATE}*.csv
depends:
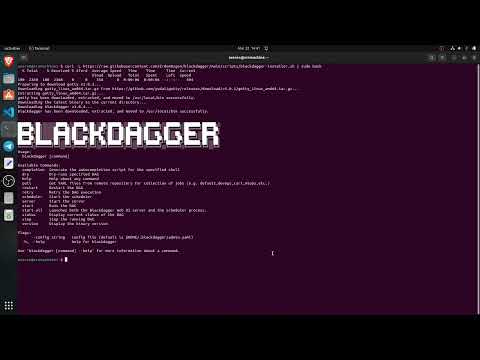
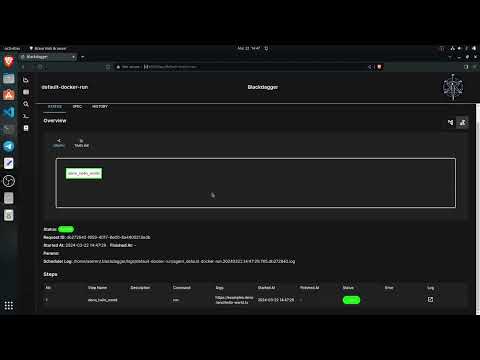
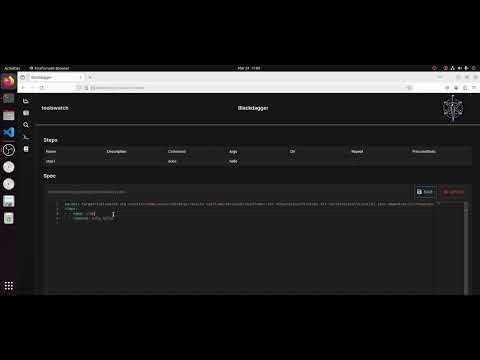
- send_reportBelow, you can find the videos that can help you to get started with Blackdagger:
| Installation and Setup of Blackdagger Video | Usage of Blackdagger Video | DAG Creation and Running in Blackdagger Video |
|---|---|---|
 |
 |
 |
Legacy systems often have complex and implicit dependencies between jobs. When there are hundreds of cron jobs on a server, it can be difficult to keep track of these dependencies and to determine which job to rerun if one fails. It can also be a hassle to SSH into a server to view logs and manually rerun shell scripts one by one. blackdagger aims to solve these problems by allowing you to explicitly visualize and manage pipeline dependencies as a DAG, and by providing a web UI for checking dependencies, execution status, and logs and for rerunning or stopping jobs with a simple mouse click.
While there are numerous workflow schedulers like Airflow available, these often necessitate the authoring of DAGs through programming languages such as Python. For legacy systems with extensive job configurations, incorporating code in languages like Perl or Shell Script can already be a complex endeavor. Introducing an additional layer with such tools can further complicate maintainability. In contrast, BlackDagger is crafted for simplicity and usability, requiring no coding skills. This makes it a perfect fit for smaller projects looking for a straightforward, self-sufficient workflow management solution.
BlackDagger simplifies workflow management by operating as a standalone command-line tool, leveraging the local file system for data storage — eliminating the need for database management systems or cloud services. It enables the definition of DAGs in an intuitive, declarative YAML format, ensuring that existing programs can be seamlessly integrated without any modifications.
Feel free to contribute in any way you want! Share ideas, questions, submit issues, and create pull requests. Check out our Contribution Guide for help getting started.
We welcome any and all contributions!
Blackdagger is committed to continuous improvement and the development of new features to enhance its usability and functionality. Our roadmap is guided by feedback from our users and our vision for making workflow management as intuitive and efficient as possible. Here's what's on the horizon:
- Enhanced User Interface: We're working on further improving the Web UI for an even more intuitive and user-friendly experience. This includes better navigation, more detailed execution logs, and streamlined DAG management.
- Increased Task Types: Adding support for more types of tasks, including advanced data processing and analytics tasks, to broaden the use cases Blackdagger can cover.
- Improved Documentation: Expanding our documentation to include more examples, use cases, and best practices to help users get the most out of Blackdagger.
- Plugin Architecture: Developing a plugin system to allow for easy integration with external tools and services, enhancing Blackdagger's versatility and adaptability.
- Advanced Scheduling Features: Implementing more sophisticated scheduling options to cater to complex workflow requirements, including conditional triggers(current will be updated) and event-driven execution.
- Security Enhancements: Strengthening security features to ensure secure execution of tasks, especially in sensitive or production environments.
- Machine Learning and AI Integration: Exploring ways to incorporate ML and AI capabilities to automate decision-making within workflows, such as dynamic adjustment of task execution based on previous outcomes.
- Community-Driven Development: Building a vibrant community around Blackdagger, encouraging contributions, and fostering an ecosystem of plugins and integrations.
- Global Adoption and Localization: Making Blackdagger accessible to a global audience through localization and support for multiple languages.
We are excited about the journey ahead and invite the community to contribute ideas, feedback, and code to help make Blackdagger the go-to solution for workflow management. Stay tuned for updates and join us in shaping the future of Blackdagger!
-
Kubernetes Executor
- Description: Executes tasks as Kubernetes jobs, allowing for scalable and efficient containerized job execution in a Kubernetes cluster.
- Use Case: Ideal for scaling tasks that require isolation, resource control, or need to run in a specific container environment.
-
Lambda Executor
- Description: Triggers AWS Lambda functions, enabling serverless execution of tasks without provisioning or managing servers.
- Use Case: Perfect for lightweight, event-driven tasks such as data transformation, real-time file processing, or integrating with AWS services.
-
Terraform Executor
- Description: Runs Terraform commands to apply infrastructure as code configurations, supporting the automated setup and teardown of cloud resources.
- Use Case: Useful for DevOps pipelines that require dynamic environment provisioning for testing, staging, or production deployments.
-
Webhook Executor
- Description: Sends data to specified URLs via webhooks, allowing for easy integration with external systems and services.
- Use Case: Ideal for triggering notifications, external workflows, or updating third-party systems as part of a workflow.
-
Machine Learning Model Executor
- Description: Executes machine learning model inference jobs, supporting various ML frameworks.
- Use Case: Can be used for batch processing of data through pre-trained models, such as image recognition, sentiment analysis, or predictive analytics.
-
Data Pipeline Executor
- Description: Manages and executes data pipeline tasks, such as ETL (Extract, Transform, Load) operations, supporting integration with popular data processing frameworks.
- Use Case: Useful for data engineering workflows, including data extraction from various sources, transformation, and loading into data stores or warehouses.
-
Browser Automation Executor
- Description: Executes browser automation scripts using tools like Selenium or Puppeteer for web scraping, automated testing, or any task requiring browser interaction.
- Use Case: Ideal for automated end-to-end web application testing, data extraction from web pages, or automating repetitive web tasks.
-
Ansible Executor
- Description: Executes Ansible playbooks for configuration management and application deployment.
- Use Case: Great for ensuring consistent environment configuration, deploying applications, and managing changes across distributed infrastructure.
-
Jupyter Notebook Executor
- Description: Executes Jupyter notebooks, allowing for data analysis and visualization tasks to be part of automated workflows.
- Use Case: Suitable for integrating data science and exploratory data analysis into automated processes, including preprocessing, analysis, and visualization.
-
IoT Device Executor
- Description: Sends commands or updates to IoT devices, supporting device management and automation across IoT networks.
- Use Case: Useful for IoT applications needing orchestrated control or updates across multiple devices, such as smart home systems, industrial automation, or health monitoring devices.
- Create more executors see in here
- Create more playbooks for Default,DevOps, DevSecOps, MLOps, MLSecOps, and Continuous Automated Red Teaming (CART) environments.
- Support for importing different DAGs within the same DAG using import statements, enabling modular workflow design.
- Implementation of centralized control, allowing BlackDagger to function as an agent for streamlined management.
- Enhancement of log collection features to include forwarding logs to a central server for aggregated analysis.
- Addition of functionality to generate reports in DOCX and PDF formats for improved documentation and reporting.
- Integration with ChatGPT and offline language models for automated document generation, enhancing documentation efficiency.
This project is licensed under the GNU GPLv3. It was forked from Dagu and has been adapted to serve a different purpose. While Dagu is an excellent project, its current objectives do not align with ours.