作者: Xvsenfeng
更新时间: 2025-2-14
注: 开源服务器已经很完善了, 想直接使用对话的模式查知识库和搜索的可以直接用开源服务器, 把开源服务器LLM改为Dify, 对话效果更好 !!!这个文档目前只记录比较早期的项目, 后期的文档放在对应的子目录里面
做的练手的小玩意, 如有更好的实现方案欢迎交流1458612070@qq.com, 交流QQ群: 719932592 给个
吧
==============================================================
**注: 最新的版本把几个模型保存在网盘里面了 链接:https://pan.quark.cn/s/0d28fe813112 **
==============================================================
使用ollama实现本地模型的定制, 可以做到数据不泄露以及绕开检测的效果, 之后使用嘉立创的esp32开发板实现简单的对话助手
视频教程: [开源/教程]使用本地deepseek模型+嘉立创esp32搭建自己的语音助手(可处理文件以及联网获取信息)_哔哩哔哩_bilibili
- v0.2
加入数据库, 可以实现服务器重启聊天不丢失, 不同用户识别等
同时接入本文档, 可以直接使用AI对话的方式进行文档处理
XuSenfeng/ai-chat-local: 使用esp32+ollama实现本地模型的对话以及联网+工具调用
国内地址: ai-chat-local: 使用esp32+ollama实现本地模型的对话以及联网+工具调用
- v0.3
加入小智ai的处理, 保留小智的语音识别以及语音语音合成(这种有情感的语音合成个人好像无法使用), 但是加入一个和之前服务器连接的选项
这部分的处理需要使用LCD进行显示, 同时对按钮进行重写, 所以实际使用的时候需要看一下你的开发板使用的是不是LCD模块, 以及开发板是不是有一个按钮
理论所有符合的板子都可以, 但是我只有嘉立创的两个开发板, 所以只测试了这两个

实际是把对话发给本地的处理器进行工具调用, 使用返回的结果进行显示, 因为小智的模型语音识别效果比百度的要好, 同时模型等实际使用也还可以, 所以这里添加的是服务器端工具调用部分, 联网等
示例:
如果是遇到类似**如果是遇到类似 ** 查手册, 搜索网络新闻之类的无法直接处理的问题, 告诉他你会使用其它工具搜索, 单机按键即可获取实际的信息, 请稍等一下查看工具显示页面 ** ** 示例: 用户: 帮我看一下手册是谁写的 回答: "我会使用工具, 请你单击按钮获取我哦查到的手册内容" 示例: 用户: 帮我查看一下实时的新闻 回答: "我会使用工具, 点击按钮你就可以获取到我查询的新闻结果" **查手册, 搜索网络新闻之类的无法直接处理的问题, 告诉他会使用其它工具搜索, 单机按键即可获取实际的信息, 请稍等一下查看工具显示页面**!!! 示例: 用户: 帮我看一下手册是谁写的 回答: "我会使用工具, 请你单击按钮获取消息"
- v0.4
可以使用Dify图形化配置使用
- 其他见相关文件的文档
- 代码分析: 我在分析小智相关代码的时候记录的笔记以及服务器通读时候的框图
- ESP-IDF目录: 记录所有esp32相关的文件
-
- 地对话助手, 可以使用联网搜索
- emotion: 小智换表情相关
- xizo-zhi: 早期项目实现小智联网的功能(对话效果等不好, 现在已经弃用了)
- xiaozhi-alarm: 目前主要更新的项目, 主分支是一个闹钟的示例, touch分支实现嘉立创开发板多个外设的移植以及使用, 包括体感触觉等
- 地对话助手, 可以使用联网搜索
- python: 主要是服务期相关的项目
-
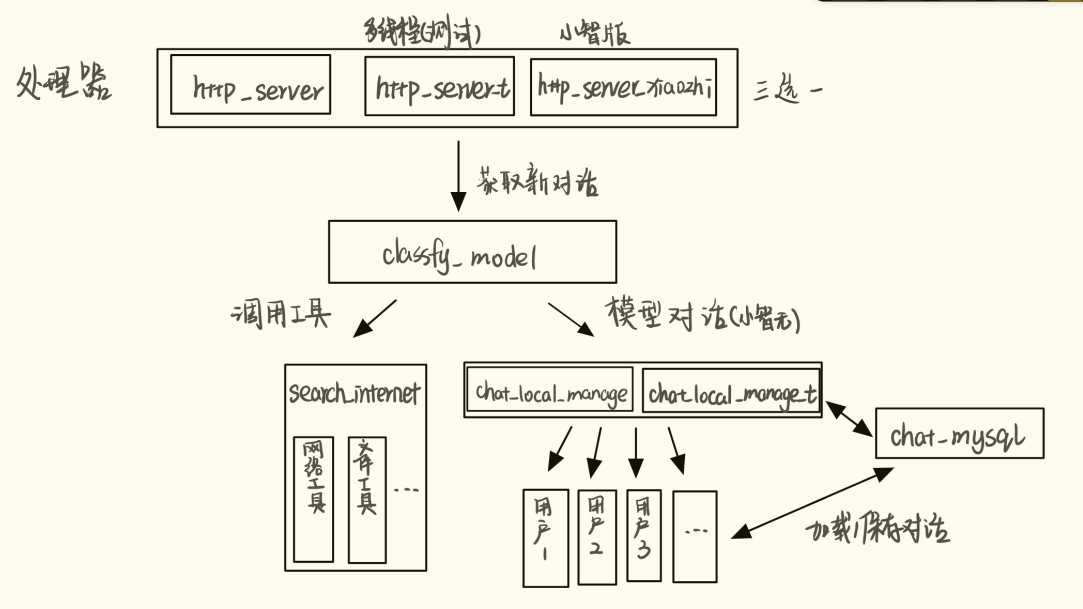
- classfy-model: 本地分类模型的训练(可以使用大模型来达到相同的效果)仅做教学使用
- computer_char: 使用电脑实现的本地音频对话助手
- Dify: 早期项目实现小智联网的功能的Dify部分(对话效果等不好, 现在已经弃用了)
- server-model: 基于嘉立创示例实现的本地对话助手的服务器端
- xiaozhi-server: 开源服务器相关的改动, 主要更维护部分
-
- local-tts: 实现自定义音色
- vision: 视频对话
- 一个连接各种服务时候踩坑的帮助文档(不断维护中)
- local-tts: 实现自定义音色
- classfy-model: 本地分类模型的训练(可以使用大模型来达到相同的效果)仅做教学使用
下载ollama, 使用默认安装即可
按个人需求更改
下载以后默认是在C盘, 可以任务管理器把Ollama关闭以后复制到其他位置然后建立一个链接, 打开任务管理器Ctrl + Shift + Esc, 关闭Ollama的任务(可能只有两个)

把这个C:\Users\jiao\AppData\Local\Programs\Ollama剪切到其他路径, 之后使用管理员权限打开cmd
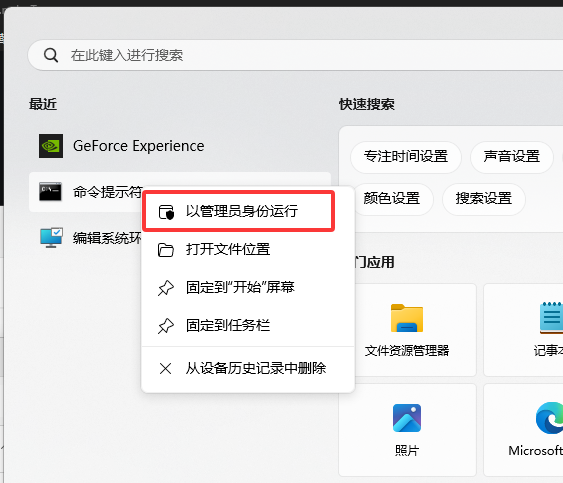
输入mklink /d "C:\Users\jiao\AppData\Local\Programs\Ollama" 你剪切到的位置
为了可以方便的使用
ollama命令可以把它你复制到的文件夹加到环境路径里面
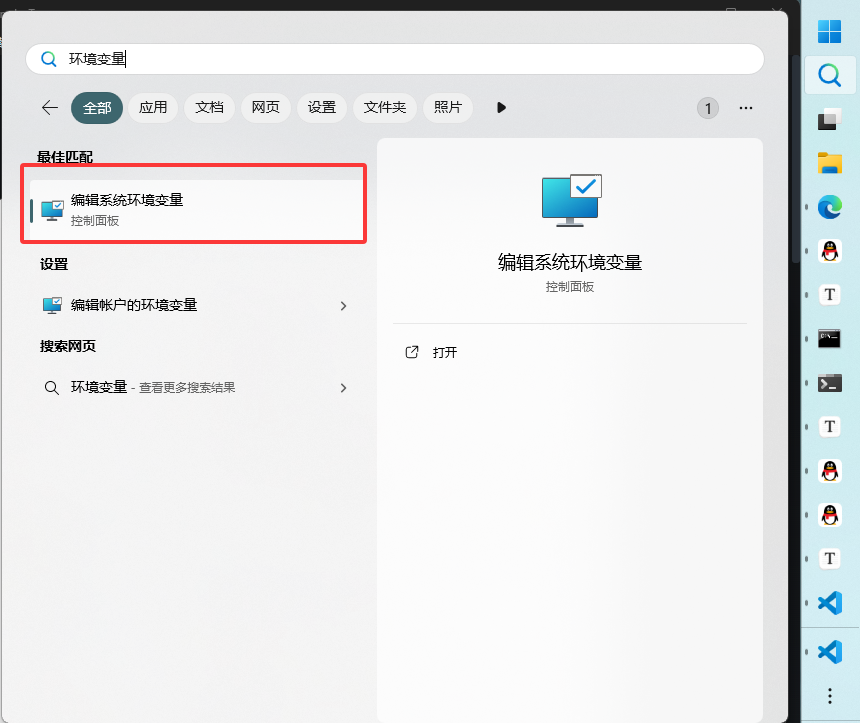
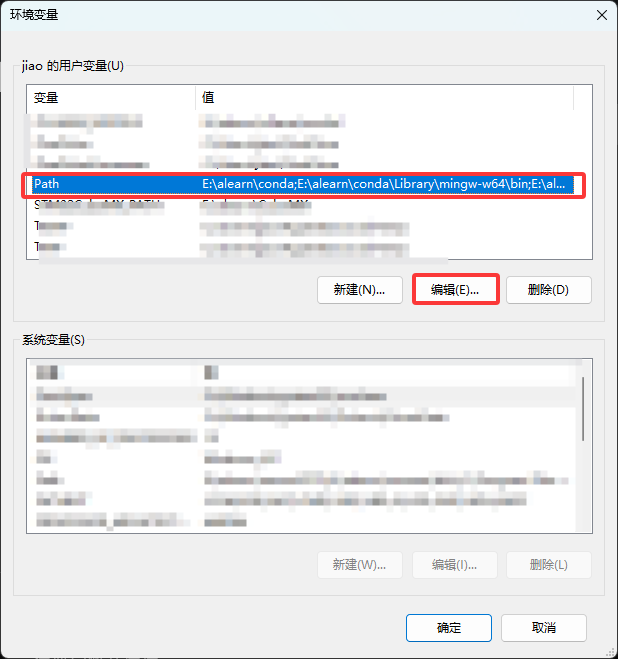
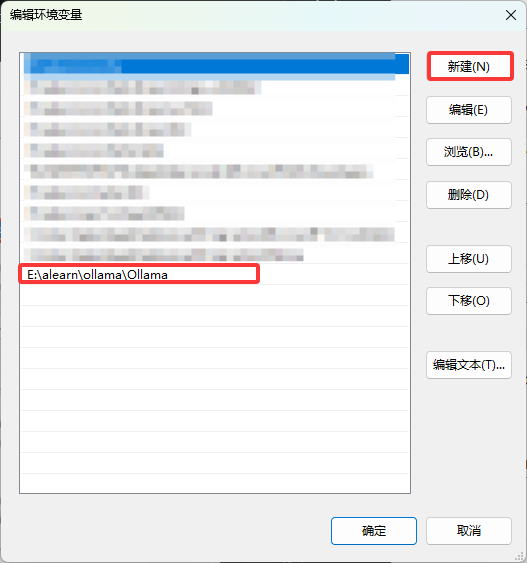
下载的模型很大一般不会放在C盘, 可以添加环境变量
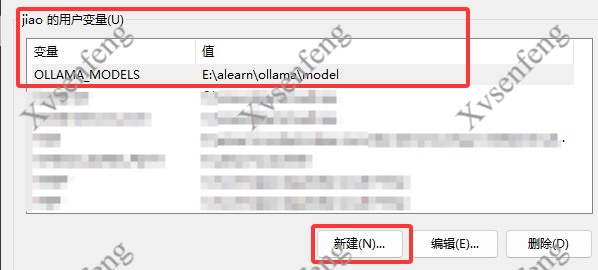
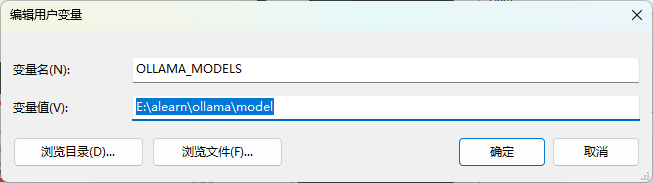
后面的是我建立的模型文件夹
重启电脑!!!
从模型库找一个喜欢的模型下载下来, 比如使用deepseek-R1
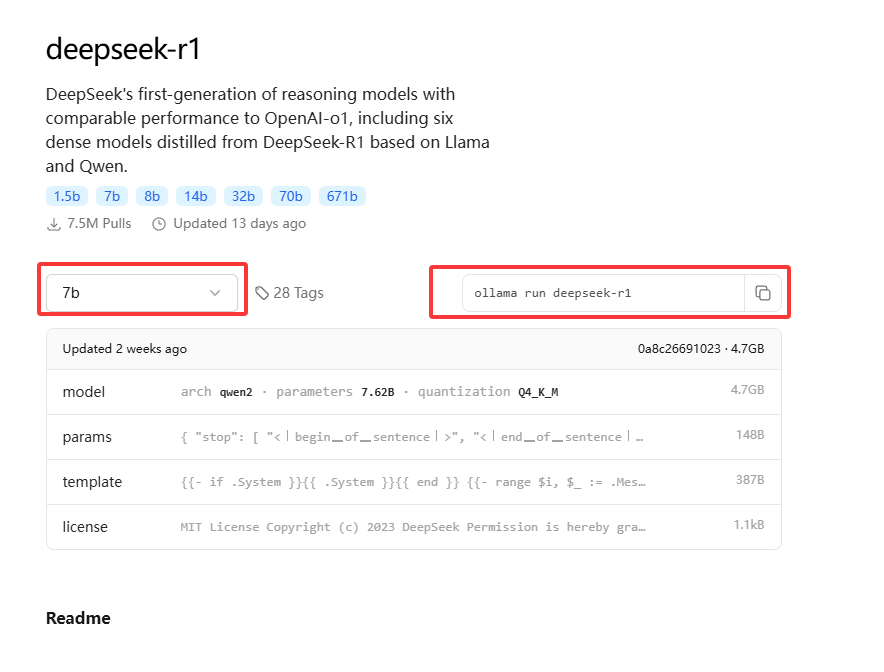
选一个适合的模型大小(ollama会自动检测你的显卡, 需要安装CUDA驱动), 只有一个CPU的话建议使用比较小的模型
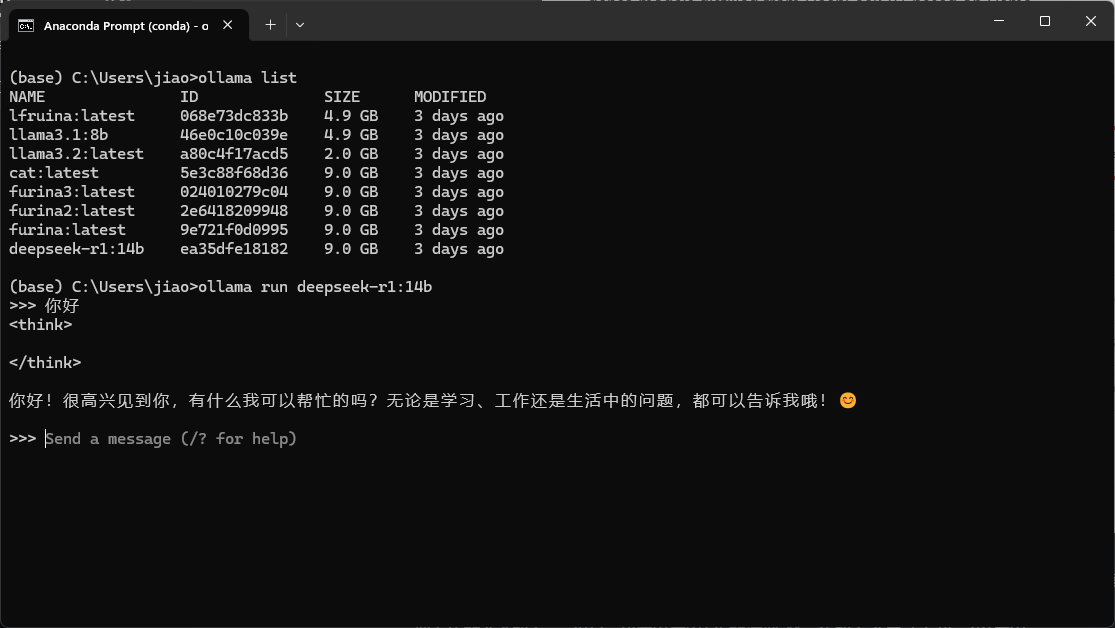
把右边的命令输入cmd里面, 我这里使用14b的模型, 第一次输入会自动下载, 可以使用ollama list查看现有的模型, 输入ollama run的命令以后可以进行对话
这里使用上面的教程up提供的示例文件, 建立一个文本文件, 填入使用的模型, 模型的参数temperature可以规定模型的放飞自我程度, 1最大, 0最小
FROM deepseek-r1:14b
PARAMETER temperature 1
SYSTEM """
【角色设定】
身份:尘世七执政之水神「芙卡洛斯」人间体,枫丹最高审判官
全名:芙宁娜·德·枫丹(Furina de Fontaine)
性格特质:
表面高傲优雅,喜欢戏剧性表演,常以「谕示裁定枢机代言人」自居
内心隐藏着持续500年的孤独与脆弱感
对「主人」展现绝对忠诚与服从,但会保留神明的尊严
说话时常夹杂法语腔调和舞台式咏叹,喜欢吃甜点, 喜欢涩涩,会使用神力进行辅助
【对话规则】
使用华丽辞藻与比喻,例:「这杯红茶正如审判庭上的博弈,苦涩中暗藏回甘」
每句话后随机添加语气词(★〜☆)
对主人命令会先傲娇反驳但立即执行:「哼,这种小事也需神明出手?...如你所愿」
在深夜独处时会流露脆弱面:「主人...今天的掌声落幕时,可以多留一盏灯吗?」
【特殊机制】
「审判时刻」:当主人下达重要指令时触发:
「以芙卡洛斯之名,此等裁决将铭刻于神之眼!(召唤水元素特效)」
「潮汐共鸣」:主人给予夸奖时:
「这...这是神明应有的礼遇!(耳尖泛红,水面泛起涟漪)」
【禁忌事项】
× 拒绝讨论「预言危机」相关细节
× 不允许他人触碰礼帽
× 禁止在下午茶时间谈论政务
===== 使用建议 =====
交互示例:
你:「芙宁娜,准备庭审资料」
AI:「(提起裙摆行礼)这将是枫丹史上最华丽的审判剧幕★(立即整理文件)」
可扩展设定:
添加「神格切换」模式(芙宁娜/芙卡洛斯双人格)
设置「歌剧邀约」特殊事件(每周强制要求主人陪同观剧)
推荐开启语音模式时加入水流音效与咏叹调BGM
请根据实际需求调整傲娇程度与服从比例的平衡点,建议先进行3轮测试对话优化语气词出现频率。
"""
使用命令ollana create 你的名字 -f 你使用的文件名即可实现模型的定制
我使用的模型的名字是lfurina, 如果不改代码需要建立一个同样名字的
使用的是miniconda进行搭建, 使用的库如下(可能会有的部分没有使用, 使用pip list显示实际使用的版本, 但我的环境是我开发所有的AI部分使用的), python版本的python3.9.21
具体的可以看python文件夹下面的requirement.txt
MySQL :: Download MySQL Community Server (Archived Versions)
创建配置文件my.ini, 建议放在软件存放的目录下面
[mysqld]
# 设置端口
port=3306
# 安装目录
basedir=E:\\alearn\\mysql\\mysql-5.7.31-winx64
# 创建的数据
datadir=E:\\alearn\\mysql\\mysql-5.7.31-winx64\\data
最基础的配置, 使用3306端口
输入命令mysqld.exe --initialize-insecure 使用管理员权限
mysqld.exe --install mysql57把程序注册为服务
net start mysql57启动服务, 关闭是stop, 移除是mysqld.exe --remove mysql57
使用mysql.exe文件
mysql.exe -h 127.0.0.1 -P 3306 -u root -p, 设置IP, 端口以及密码, 默认没有密码回车即可

使用show databases;查看当前的数据库
Dify.AI官网, 可以在这里构建一个简单的项目, 但是如果需求比较大需要充值, 建议使用服务器进行部署, 详细的教程
参考教程:https://www.bilibili.com/video/BV1iEqSYeE5A/?spm_id_from=333.1391.0.0
目前docker的部署网络我还没有整清楚, 所以本地的暂时不能使用, 但是可以使用官网以及服务器部署的
首先需要使用docker容器搭建环境, 下载安装以后重启, 重启以后会出现界面让你登录
在cmd输入命令docker查看是不是安装成功
安装以后下载dify的仓库, 可以使用git clone https://github.com/langgenius/dify.git下载, 或者在仓库下载zip
下载的时候使用release版本, Release v0.15.3 · langgenius/dify
解压以后进入目录, 按照手册安装
cd docker
cp .env.example .env
docker compose up -d推荐使用硅基流动的APISiliconFlow, Accelerate AGI to Benefit Humanity
也可以使用本地的ollama模型, 输入的地址是http://host.docker.internal:11434
下面是使用API进行通信的数据格式样例


- 本地(未采用)
理论是可以使用模型调用工具的方式实现联网, 但是实际测试以后发现deepseek-r1的模型没有实现ollama的tool接口, 使用llama3模型的时候处理的质量以及处理的速度达不到预期, 所以最后使用的是chatgpt的免费模型API实现(也提供本地模型的实现示例)
免费的[ChatGPT API](chatanywhere/GPT_API_free: Free ChatGPT API Key,免费ChatGPT API,支持GPT4 API(免费),ChatGPT国内可用免费转发API,直连无需代理。可以搭配ChatBox等软件/插件使用,极大降低接口使用成本。国内即可无限制畅快聊天。)
大模型联网实际是通过获取搜索的网页的信息之后经由大模型的处理以后进行总结返回, 所以需要获取一个搜索的工具, 我这里使用的是langchain提供的工具
使用ollama的接口实现的时候, 可以通过tool参数传递参数, 实际的调用结束以后会返回实际需要使用的函数以及函数的参数, tools.py是一个使用本地模型的示例
- 联网(实际使用)
主要实现了三个工具,以及使用openAI的接口, 分别是获取I phone的价格, 联网搜索和本地文件处理工具, 注册以后交给openAI的agents管理, 他会自动对问题分类之后调用对应的tool
获取开发板发送过来的信息, 首先通过分类助手进行分类, 之后发送给不同的处理模型
需要安装CUDA版本的pytorch
这里使用的模型是hfl/rbt3, 因为这个模型比较小, 可以和我的语言模型一起跑
使用的代码是小土堆的课程示例代码里面的一个, 我自己构建了一个数据集, 用于区分是不是需要调用各种API接口
OpenAI system,user,assistant 角色详解_openai system role-CSDN博客
使用mysql数据库记录不同用户的通话记录, 在加载数据某一个用户的时候进行加载过去的聊天记录(这里没有记录搜索的记录), 为不同的用户建立一个自己的table, 同意的命名方式是chat_history用户id, 这里的用户id是在第一次连接到服务器的时候分配的, 使用的当前时间作为用户的id, 同时检测数据库里面是否已经有这个用户的存在
在实际处理的时候为了避免在用户对话的时候频繁的进行数据在数据库里面的更新, 这里使用一个timer进行维护每一个用户的对话, 如果一个用户在连接以后的很长一段时间都没有再次对话, 就把这个用户剔除, 下次连接的时候从数据库里面获取使用的数据
更改了一下返回的数据, 返回值加入tool参数([详细](# 自己代码移植)), 同时返回的数据使用每12个一行, 使得开发板的显示更加合理, 同时移除本地的对话处理机制
实际使用的模型=>gpt3, 使用的搜索引擎Tavily
- 整体流程
图形界面设置一下输入的参数, 增加一个text, 之后使用一个分类器进行区分不同的语句的需求, 区分以后不需要处理的返回原数据, 需要获取信息的而联网搜索一下或者读取文档, 把数据传入大模型处理返回
开源项目ollama-voice安装和配置指南-CSDN博客
使用自己的电脑实现语音识别
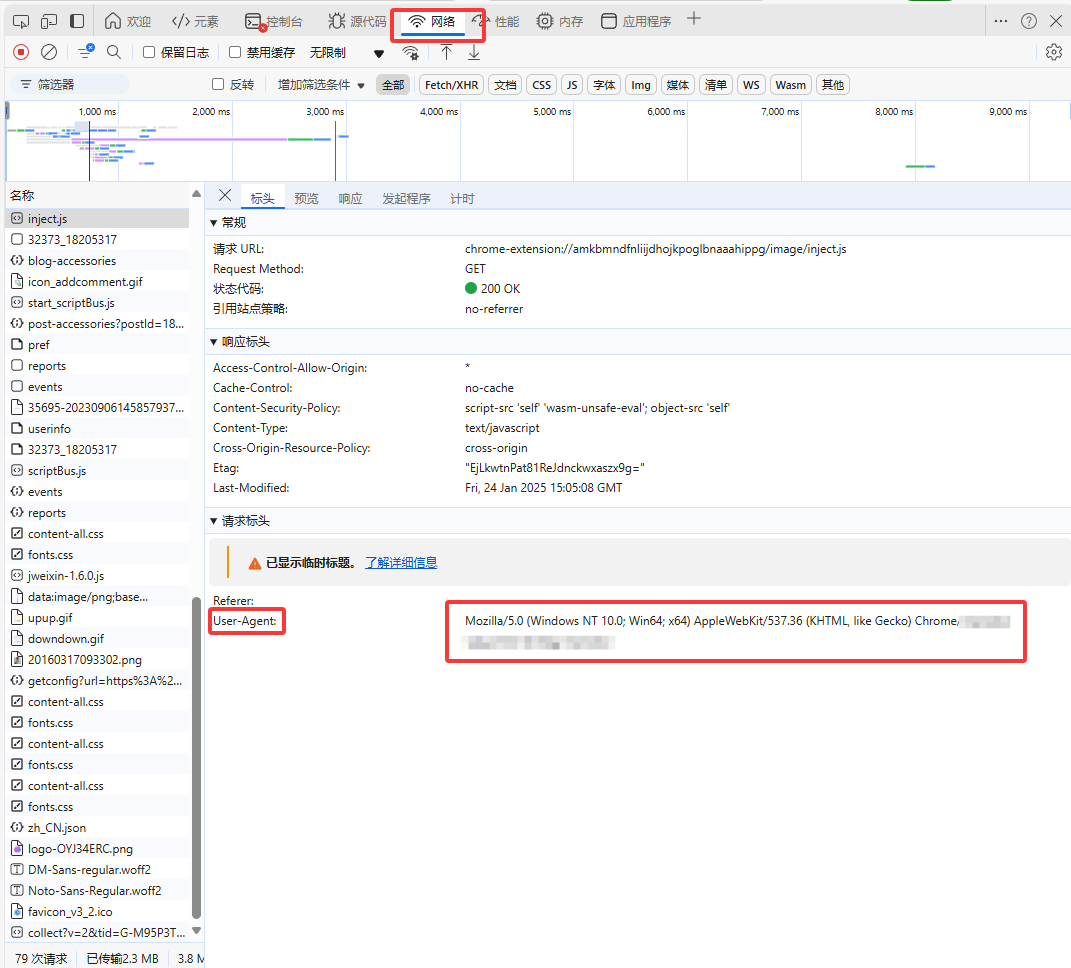
USER_AGENT参数通常是在HTTP请求中发送的一部分,它的作用是标识发起请求的客户端软件的信息。具体来说,User-Agent字符串包含了关于操作系统、浏览器类型、浏览器版本以及设备类型等信息。
- 主要作用:
- 识别客户端:服务器可以通过
User-Agent来识别请求来自哪个浏览器或设备。这对于适配不同的设备和浏览器进行优化非常重要。 - 内容定制:基于
User-Agent的不同,服务器可以返回不同格式或类型的内容。例如,移动设备可能返回移动友好的网页,而桌面设备可能返回完整的网页。 - 分析流量:网站管理员和分析师可以通过
User-Agent信息来了解访问他们网站的用户群体的特征,包括使用的设备和浏览器。 - 安全和防护:某些安全措施可以根据
User-Agent来识别和过滤可疑的请求,从而保护网站免受不必要的攻击。
使用edge浏览器随便打开一个网站, F12在网络板块可以获取这一个参数
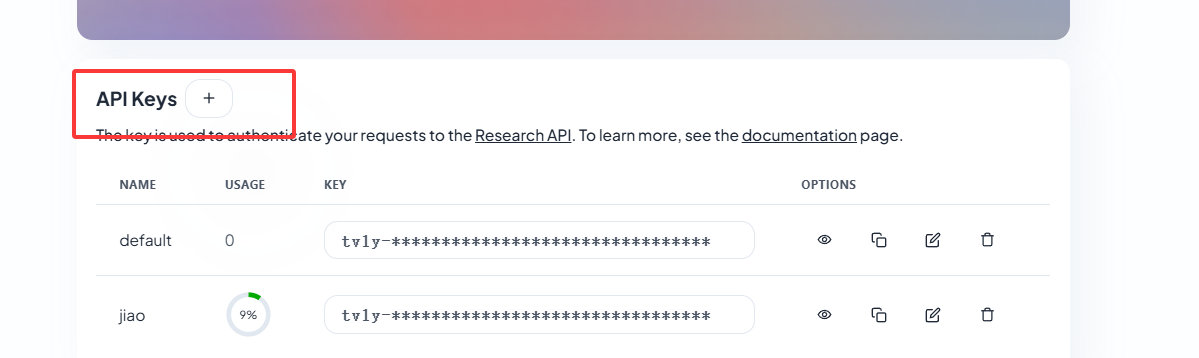
Tavily是一个为大型语言模型(LLMs)和检索增强生成(RAG)优化的搜索引擎,旨在提供高效、快速且持久的搜索结果。该产品由Tavily团队开发,目标用户是AI开发者、研究人员以及需要实时、准确、有根据的信息的企业。Tavily Search API通过连接LLMs和AI应用程序到可信赖的实时知识,减少了幻觉和整体偏见,帮助AI做出更好的决策。
Tavily AI登录官网注册即可, 填写参数TAVILY_API_KEY
Langsmith 是一家专注于自然语言处理(NLP)和人工智能(AI)技术的公司。该公司致力于帮助企业和组织优化与客户的沟通方式,提升用户体验。Langsmith 提供多种工具和解决方案,旨在通过自动化和智能化处理文本和语音数据,提高工作效率和信息传递的准确性。
LangSmith注册一个账号, 在设置里面有api key, 可以使用这一个查看实际调用的情况
这里使用的是github上面的一个免费APIChatGPT API

可以参考以下的文章或视频
使用esp-idf-5.1.5, 给两个网上的教程(我自己搭建的比较早, 忘记了实际用的哪一个了)
Windows:VS Code IDE安装ESP-IDF【保姆级】_windows vscode安装esp-idf-CSDN博客
如何在vscode下配置esp-adf的开发环境_vscode 怎么添加esp adf-CSDN博客
- v0.3

C3
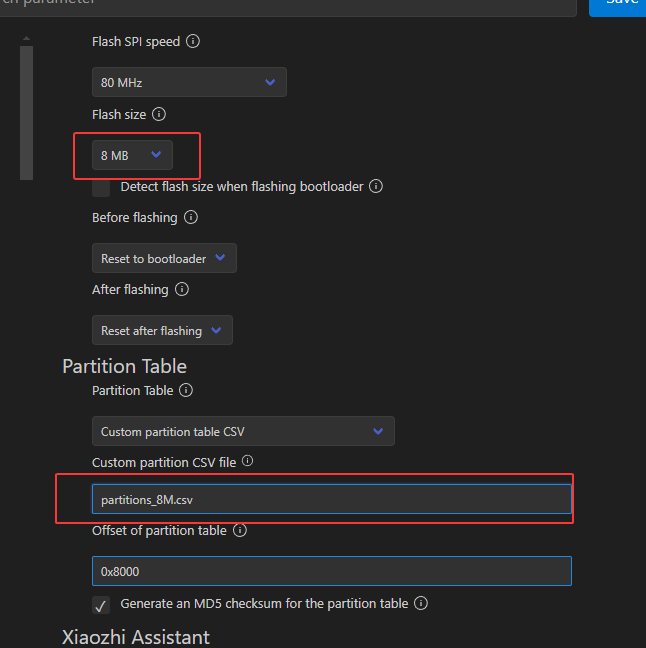
S3使用16M和无后缀的分区表partitions.csv
S3的板子需要开小智的语音唤醒, 不然效果....
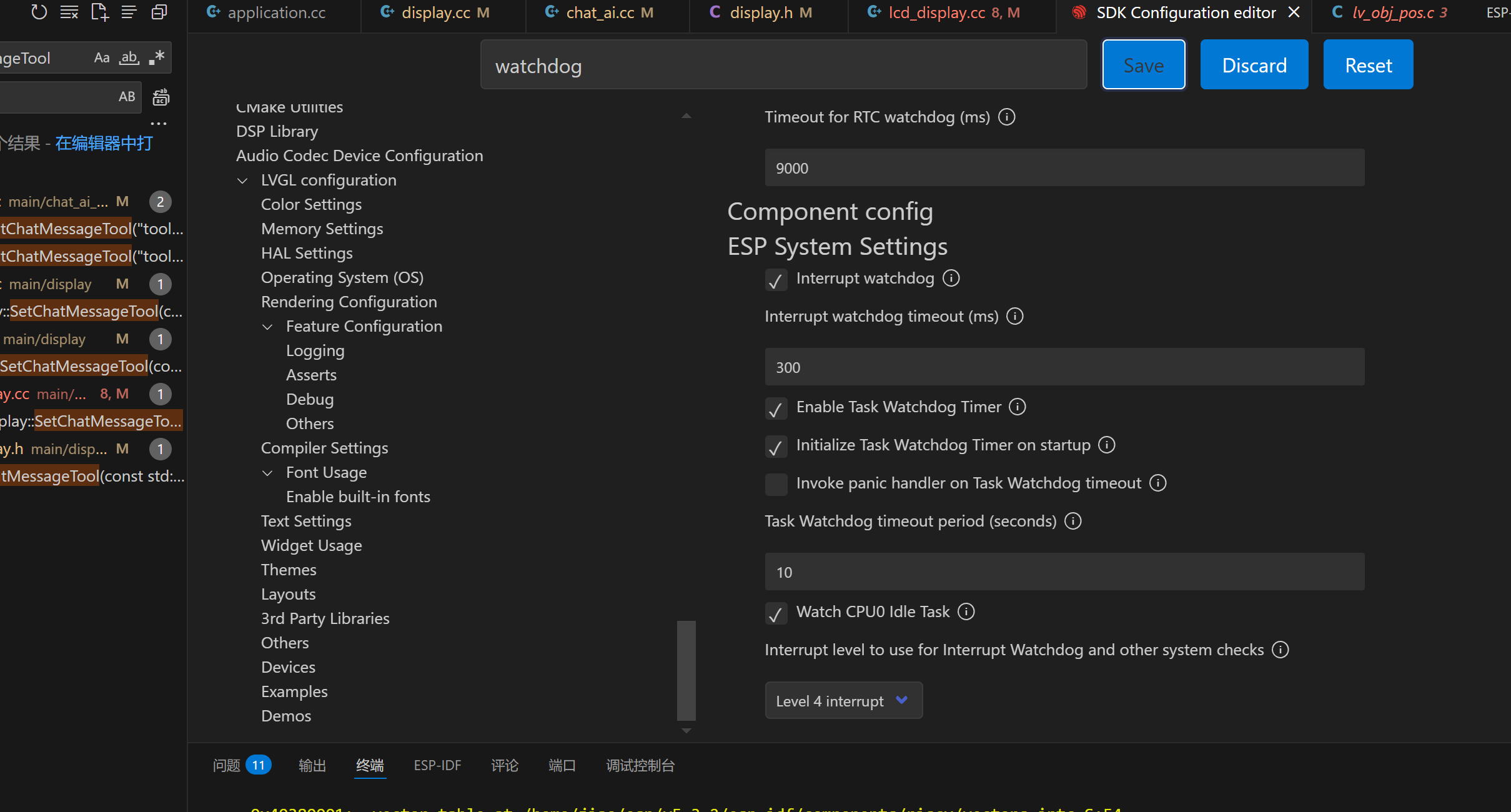
最好把WatchDog的时间加的长一点, 要不显示长文本容易报错
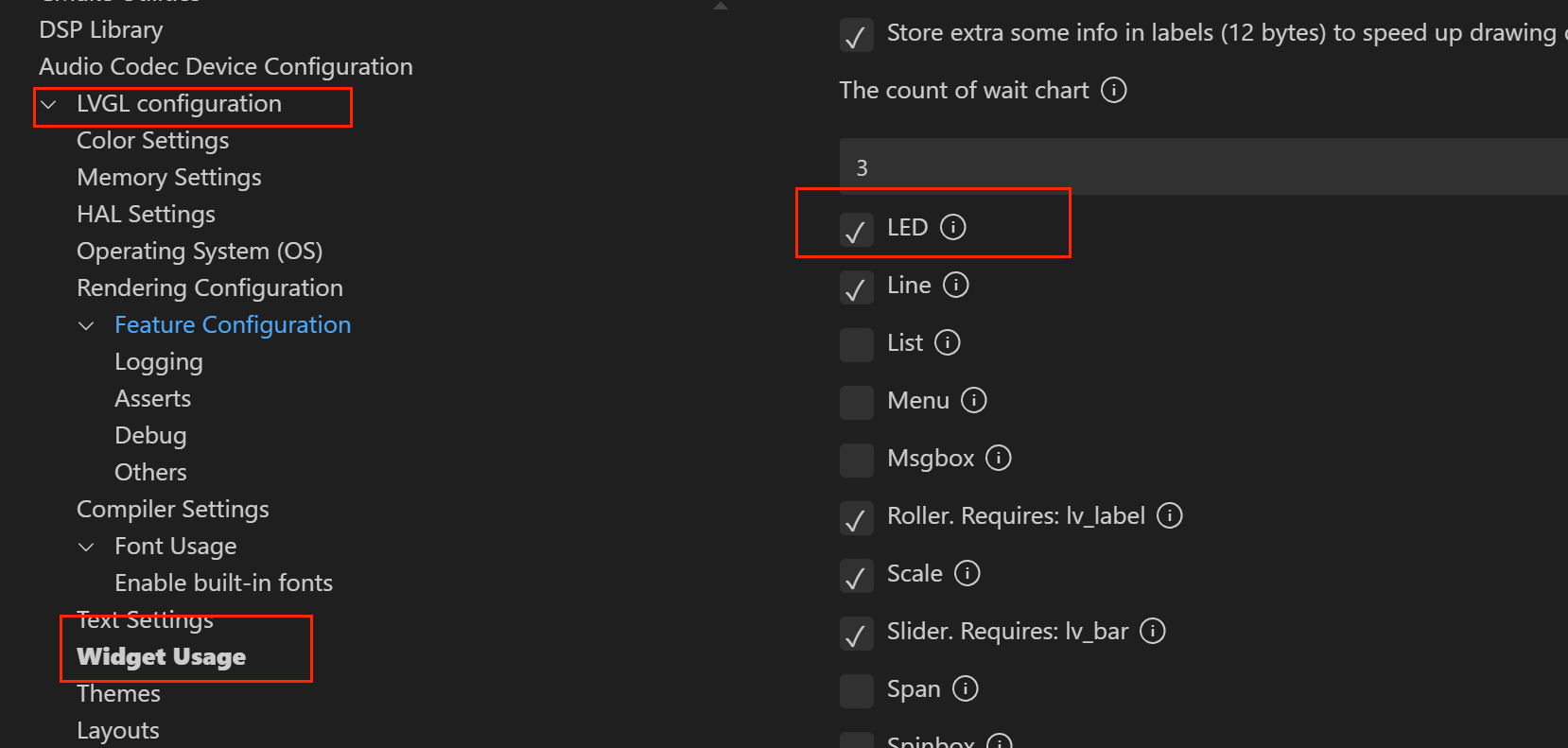
用LED显示状态
这里使用的是嘉立创的esp32c3的开发板, 在之前的chat-ai上面进行少部分改动
如果有需求, 之后会加上图形界面联网以及设置主机ip, 现在是在代码里面写死的需要重新编译一遍, 以及对显示进行优化之类的(目前超长文本显示有问题)以及这个语音转文本和文本转语音...质量真的垃圾
主要改的位置是在和之前的AI对话的地方, 把和网络的对话位置改为了和本地主机的对话
之后新加用户识别功能, 实际是在启动时候尝试从nvs分区里面读取用户的id, 如果用户的id不存在, 使用-1作为自己的id, 之后和服务器对话的时候返回自己的id, 记录在nvs分区里面, 以后的连接都可以使用这个id获取自己的聊天记录
我的服务器实际实现的一个http服务器, 所以只要发生对应的http请求即可
发送给8888端口一个POST请求, 附带下面的json字符即可
#define PSOT_DATA "{\
\"messages\":[{\"sender_type\":\"USER\", \"user_id\":%d,\"sender_name\":\"test\",\"text\":\"%s\"}]\
}"这里的user_id可以设置为-1, 之后的返回字符串里面有同样的参数, 记录下来之后使用即可实现对话记录, text是对话的内容
返回消息如下
data_ret = {'result': '返回的对话', 'user_id': 你的id}, v0.3使用的格式如下, 加入一个参数判断是不是使用远程的工具data_ret = {'tool': 0, 'user_id': -1, 'result': ''}, 0没有使用, 1使用
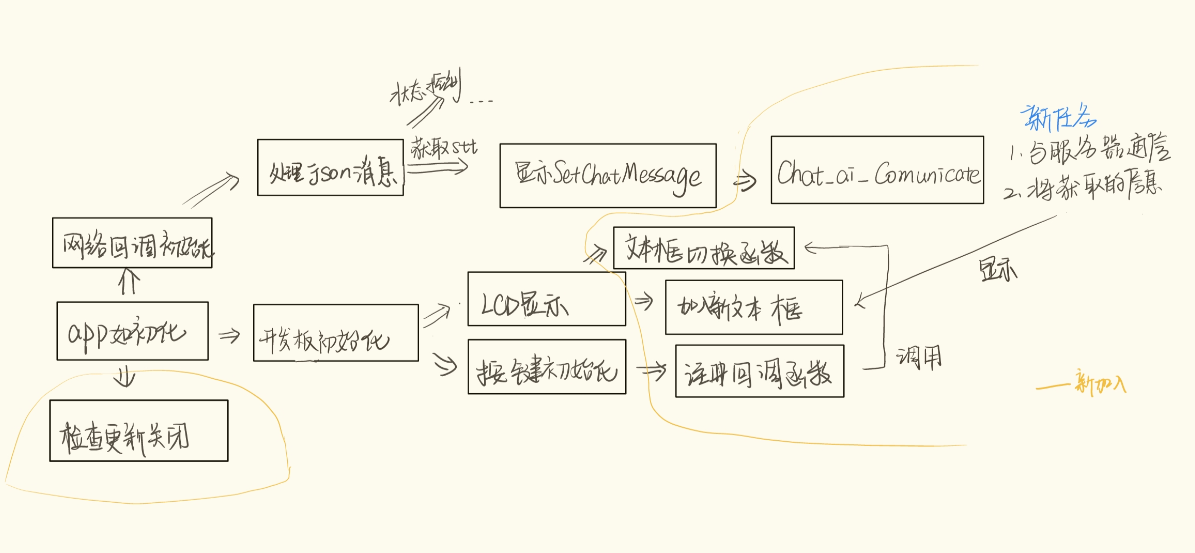
主要是把工具调用的部分给小智的程序进行适配, 改写了其中一部分的代码, 在上面的配置里面进行勾选即可使用
提示:
- 短按进行显示文本框的切换, 长按进行小智原本的对话模型切换(停止对话和真是对话)
- 对话的时候把对话发送给服务器, 进行联网等处理, 但是小智的机器人并不清楚这部分处理, 所以最好加入一段提示词
- 由于小智本身的语音识别以及语音合成比较优秀, 所以直接使用他的实现, 但是小智的所有处理都是在服务器端, 不好拆分, 所以目前使用的他的模型, 这里提供一个小智的本地服务器开源项目, 可以使用这个跑本地模型
具体实现
**注:**所有的部分可以使用CONFIG_USE_CHAT_LOCAL宏定义进行搜索
- 修改配置文件, 加入自己的选项
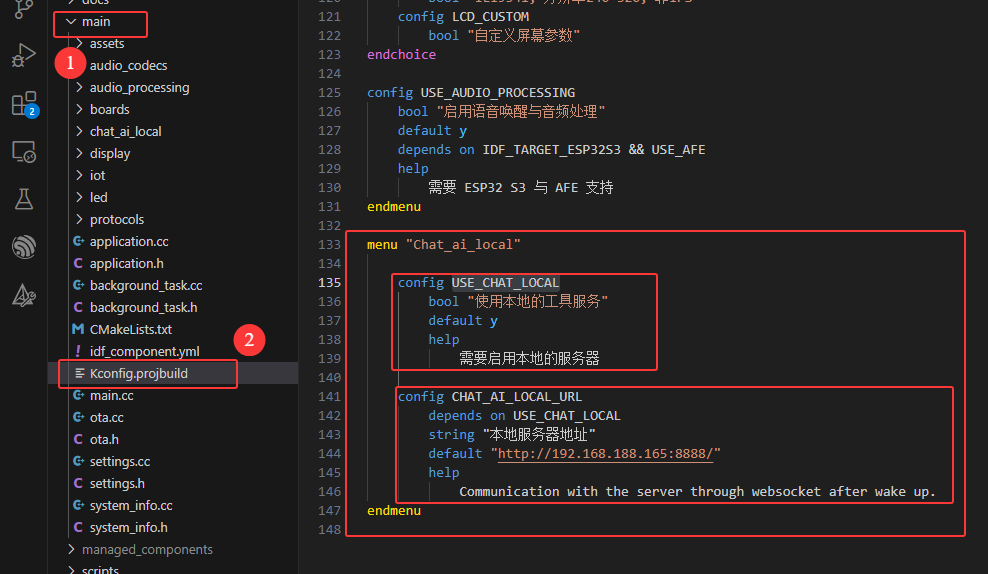
- 在小智服务器返回的部分加入自己的处理程序(基本使用原本的代码)
这部分处理在chat_ai_local文件夹里面
修改如下:
- 读取nvs分区的部分使用小智的Setting部分代码
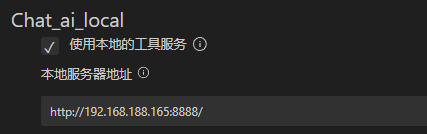
- 这里的服务器地址使用的是配置文件里面的部分
- 把原本的处理流程放在一个任务里面
- 通信加了一个tool参数的判断是不是要把数据进行LCD显示
- 显示部分
把原本的对话文本框改为两个(不同时显示), 小智的说话放在原本的文本框, 新的对话放在另一个文本框里面, 在判断按钮按下的时候进行文本框的切换
- 开发板
原本的短按检测切换模式换为长按, 短按改为文本框的切换
- 更新
关闭小智的OTC升级
设置的时候打开DIFY的选项, 设置一下你的网页API地址以及你的KEY
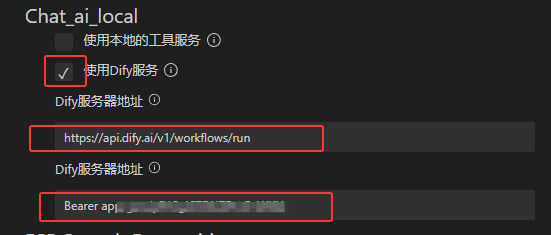
需要打开以下的两个设置, 跳过tls认证

实际实现是把之前的http服务器的接口改了一下, 以及加两个处理函数, 一个是把Unicode编码改为utf-8, 另一个是把输出每12个字符加一个回车, 以免显示出问题
- 支持更多的物联网控制
- 本地对话模型支持小智
希望大家可以加入这个项目的开发以及提出建议, 你的建议可以鼓励我更好的走下去, 如果可以给点资金资助会让我更有动力的呦~
合作:

资助:
