- About
- Installation
- Data Aquisition
- Flair Classification
- Deploying as a Web Service
- Build on Google Colab
- References
This repo illustrates the task of data aquisition of reddit posts from the /india subreddit, classification of the posts into 11 different flairs and deploying the best model as a web service.
NOTE: In case the installation does work as expected, move to Build on Google Colab to try the project without installing locally. All results can be replicated on google colab easily.
The following installation has been tested on MacOSX 10.13.6 and Ubuntu 16.04.
This project requires Python 3 and the following Python libraries installed(plus a few other s depending on task):
- Clone the repo
git clone https://github.com/akshaybhatia10/Reddit-Flair-Detection/-.git
cd Reddit-Flair-Detection/- Run
pip install -r requirements**Note: The notebook requires a GCP account, a reddit account and CloudSDK installed. If you want to use the dataset to get started with running the models instead building the dataset yourself, download the datasets using:
To download the datasets from s3
wget --no-check-certificate --no-proxy "https://s3.amazonaws.com/redditdata2/train.json"
wget --no-check-certificate --no-proxy "https://s3.amazonaws.com/redditdata2/test.json"We will reference the publically available Reddit dump to here. The dataset is publically available on Google BigQuery and is divided across months from December 2015 - October 2018. BigQuery allows us to perform low latency queries on massive datasets. One example is this. Unfortunately the posts have not been tagged with their comments. To extract this information, in addition to BigQuery, we will use PRAW for this task.
The idea is to randomly query a subset of posts from December 2015 - October 2018. Then for each of the post, use praw to get comments for each one. To build a balanced dataset, we will limit the number of samples for each flair at 2000 and further randomly sample from the queried records.
To get started, follow here. (Note: The notebook requires a GCP account, a reddit account and CloudSDK installed.)
| Feature Name | Type | Description |
|---|---|---|
| author | STR | author name |
| comments | LIST | list of top comments(LIMIT 10) |
| created_utc | INT | timestamp of post |
| link_flair_text | STR | flair of the post |
| num_comments | INT | number of comments on the post |
| score | INT | score of the post (upvotes-downvotes) |
| over_18 | BOOL | whether post is age restricted or not |
| selftext | STR | description of the post |
| title | STR | title of the post |
| url | STR | url associated with the post |
This stores the queried records in a mongoDB database 'dataset' within the collection 'reddit_data'. To export the mongoDB colection to json, run:
mongoexport --db dataset -c reddit_dataset --out ./reddit_data.jsonTo import this json to your system, run:
mongoimport --db dataset --collection reddit_dataset --file ./reddit_data.json| Description | Size | Samples |
|---|---|---|
| dataset/train | 31MB | ~16400 |
| dataset/test | 7MB | ~5000 |
We are considering 11 flairs. The number of samples per set is:
| Label | Flair | Train Samples | Test Samples |
|---|---|---|---|
| 1. | AskIndia | 1523 | 477 |
| 2. | Politics | 1587 | 413 |
| 3. | Sports | 1719 | 281 |
| 4. | Food | 1656 | 344 |
| 5. | [R]eddiquette | 1604 | 396 |
| 6. | Non-Political | 1586 | 414 |
| 7. | Scheduled | 1596 | 372 |
| 8. | Business/Finance | 1604 | 396 |
| 9. | Science/Technology | 1626 | 374 |
| 10. | Photography | 554 | 86 |
| 11. | Policy/Economy | 1431 | 569 |
Note: The notebooks download the training and test set automatically.
This section describes different models implemeted for the task of flair classification. We ideally want to classify the post as soon as it is created so we mostly use the title and body of the post as inputs to the models.
In this example, we perform a basic exploration of all features. We then run a simple XGBoost model over some meta features. This is followed by running 3 simple baseline algorithms using TFIDF on title and post as features.
In this section, we implement various RNN based architectures on the reddit post title concatenated with the post body feature. Also, each model uses the pretrained glove embeddings as inputs to the model.(without fine tuning)
This model consists of a single layer vanilla GRU with a softmax classifier.

Here we implement concat pooling with a GRU. (See notebook for more details.)

This model uses a RNN encoder conditioned with a scaled dot product self attention layer with a softmax classifier.
NOTE: Most of the code in this notebook is referenced from the pytorch implementation of BERT in this repo.
In this notebook, we use the pretrained language model BERT for the flair classification. BERT fine-tuning requires only a few new parameters added. For our purpose, we get the prediction by taking the final hidden state of the special first token [CLS], and multiplying it with a small weight matrix, and then applying softmax .Specifically, we use the uncased 12 head, 768 hidden model.
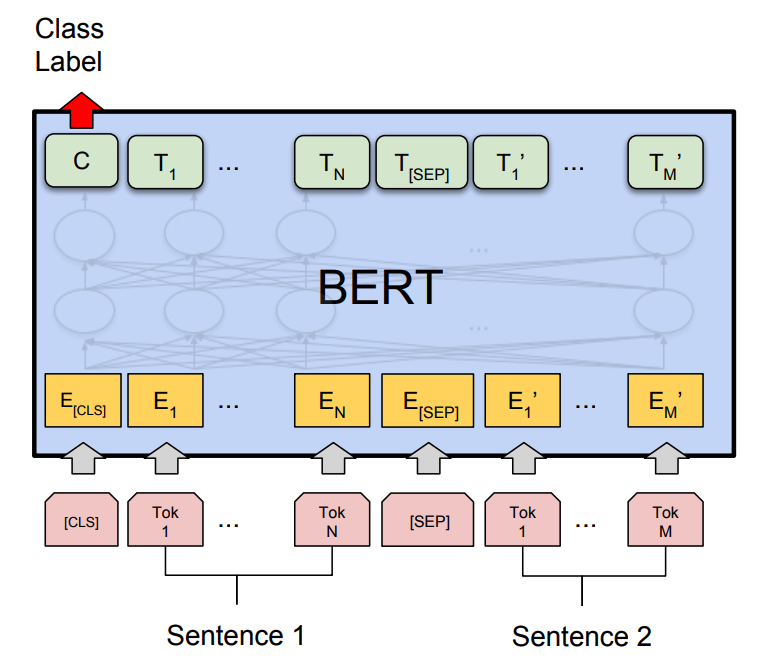
The BERT model gives and best performance and is used in the deployed web app. Download the trained model using:
wget --no-check-certificate --no-proxy "https://s3.amazonaws.com/redditdata2/pytorch_model.bin"The results of different models on test set:
| Model | Accuracy | |
|---|---|---|
| Logistic Regression | 55.45 | |
| MultinomialNB | 54.70 | |
| SGD | 56.30 | |
| Single Layer Simple GRU/LSTM | 59.36 | |
| GRU with Concat Pooling | 61.62 | |
| Bi-GRU with Self Attention | 54.36 | |
| BERT | 67.1 |
The best model - BERT is deployed as a web app. Check the live demo here. Due to the large model size, the app was deployed using Google Compute Engine platform rather a free service like heroku(due to its limited slug size). All the required files can be found here
| 1 | 2 |
|---|---|
Google Colab lets us build the project without installing it locally. Installation of some libraries may take some time depending on your internet connection.
To get started, open the notebooks in playground mode and run the cells(You must be logged in with your google account and provide additional authorization). Also since mongoDB cannot be run in a Colab environment, the data aquisition notebook cannot run in Google Colab.
- Data Exploration and Baseline Implementations
- Simple GRU/LSTM, GRU with Concat Pooling and GRU/LSTM with Self Attention
- Classification using BERT
- Cho et. al. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. 2014
- Devlin et. al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. 2018
- Jeremy Howard, Sebastian Ruder. ULMFIT. 2018
- Vasvani et. al. Attention is all you need. Nips 2017
- Pytorch Implementation of BERT - HuggingFace Github repo