Described the basics of git
** Hands-on Git **
Git is a distributed revision control and source code management system with an emphasis on speed.
Git was initially designed and developed by Linus Torvalds for Linux kernel development.
Git is a free software distributed under the terms of the GNU General Public License version 2.
VCS is a software that helps software developers to work together and maintain a complete history of their work.
Listed below are the functions of a VCS:
- Allows developers to work simultaneously.
- Does not allow overwriting each other’s changes.
- Maintains a history of every version.
- Centralized version control system (CVCS).
- Distributed/Decentralized version control system (DVCS).
Distributed version control systems (DVCSs) solve different problems than Centralized VCSs. Comparing them is like comparing hammers and screwdrivers.
systems are designed with the intent that there is One True Source that is Blessed, and therefore Good. All developers work (checkout) from that source, and then add (commit) their changes, which then become similarly Blessed. The only real difference between CVS, Subversion, ClearCase, Perforce, VisualSourceSafe and all the other CVCSes is in the workflow, performance, and integration that each product offers.
systems are designed with the intent that one repository is as good as any other, and that merges from one repository to another are just another form of communication. Any semantic value as to which repository should be trusted is imposed from the outside by process, not by the software itself.
The real choice between using one type or the other is organizational -- if your project or organization wants centralized control, then a DVCS is a non-starter. If your developers are expected to work all over the country/world, without secure broadband connections to a central repository, then DVCS is probably your salvation.
- Free and open source
- Fast and small
- Implicit backup
- Security
- No need of powerful hardware
- Easier branching
Git uses a common cryptographic hash function called secure hash function (SHA1), to name and identify objects within its database. Every file and commit is check-summed and retrieved by its checksum at the time of checkout. It implies that, it is impossible to change file, date, and commit message and any other data from the Git database without knowing Git.
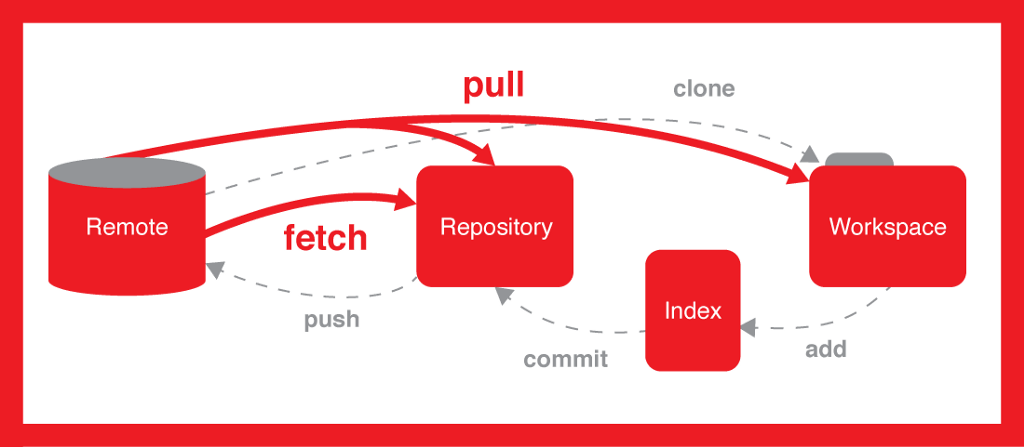
Every VCS tool provides a private workplace as a working copy. Developers make changes in their private workplace and after commit, these changes become a part of the repository. Git takes it one step further by providing them a private copy of the whole repository. Users can perform many operations with this repository such as add file, remove file, rename file, move file, commit changes, and many more.
The working directory is the place where files are checked out. In other CVCS, developers generally make modifications and commit their changes directly to the repository. But Git uses a different strategy. Git doesn’t track each and every modified file. Whenever you do commit an operation, Git looks for the files present in the staging area. Only those files present in the staging area are considered for commit and not all the modified files.
- User can modify the file in the local repository.
- Add the modified files to the staging area.
- And perform commit operation that moves the files from the staging area. After push operation, it stores the changes permanently to the Git repository.

I modified a file called test.js and want to push to the remote by staging and committing.
#First add the files
git add test.js
#adds file to the staging area
git commit -m "Added test scenarios in the test.js file"
#push to the remote server now
git push origin masterBlob stands for Binary Large Object. Each version of a file is represented by blob. A blob holds the file data but doesn’t contain any metadata about the file. It is a binary file, and in Git database, it is named as SHA1 hash of that file. In Git, files are not addressed by names. Everything is content-addressed.
Tree is an object, which represents a directory. It holds blobs as well as other sub-directories. A tree is a binary file that stores references to blobs and trees which are also named as SHA1 hash of the tree object.
Commit holds the current state of the repository. A commit is also named by SHA1 hash. You can consider a commit object as a node of the linked list. Every commit object has a pointer to the parent commit object. From a given commit, you can traverse back by looking at the parent pointer to view the history of the commit. If a commit has multiple parent commits, then that particular commit has been created by merging two branches.
Branches are used to create another line of development. By default, Git has a master branch, which is same as trunk in Subversion. Usually, a branch is created to work on a new feature. Once the feature is completed, it is merged back with the master branch and we delete the branch. Every branch is referenced by HEAD, which points to the latest commit in the branch. Whenever you make a commit, HEAD is updated with the latest commit.
Tag assigns a meaningful name with a specific version in the repository. Tags are very similar to branches, but the difference is that tags are immutable. It means, tag is a branch, which nobody intends to modify. Once a tag is created for a particular commit, even if you create a new commit, it will not be updated. Usually, developers create tags for product releases.
Clone operation creates the instance of the repository. Clone operation not only checks out the working copy, but it also mirrors the complete repository. Users can perform many operations with this local repository. The only time networking gets involved is when the repository instances are being synchronized.
Pull operation copies the changes from a remote repository instance to a local one. The pull operation is used for synchronization between two repository instances. This is same as the update operation in Subversion.Push operation copies changes from a local repository instance to a remote one. This is used to store the changes permanently into the Git repository. This is same as the commit operation in Subversion.
HEAD is a pointer, which always points to the latest commit in the branch. Whenever you make a commit, HEAD is updated with the latest commit. The heads of the branches are stored in .git/refs/heads/ directory.
Revision represents the version of the source code. Revisions in Git are represented by commits. These commits are identified by SHA1 secure hashes.
URL represents the location of the Git repository. Git URL is stored in config file.
[ubuntu ~]$ sudo apt-get install git-core
[sudo] password for ubuntu:
[ubuntu ~]$ git --version
git version 2.15.1Git provides the git config tool, which allows you to set configuration variables. Git stores all global configurations in .gitconfig file, which is located in your home directory. To set these configuration values as global, add the --global option, and if you omit --global option, then your configurations are specific for the current Git repository.
You can also set up system wide configuration. Git stores these values in the /etc/gitconfig file, which contains the configuration for every user and repository on the system. To set these values, you must have the root rights and use the --system option.
$ git config --global user.name "Git user"$ git config --global user.email "gituser@xyz.com"You pull the latest changes from a remote repository, and if these changes are divergent, then by default Git creates merge commits. We can avoid this via following settings.
$ git config --global branch.autosetuprebase alwaysThe following commands enable color highlighting for Git in the console.
$ git config --global color.ui true
$ git config --global color.status auto
$ git config --global color.branch auto$ git config --global core.editor vim$ git config --global merge.tool vimdiff$ git config --list
//output
user.name=Git user
user.email=gituser@xyz.com
push.default=nothing
branch.autosetuprebase=always
color.ui=true
color.status=auto
color.branch=auto
core.editor=vim
merge.tool=vimdiff- Clone the git repository as the working copy.
- Modify the working copy.
- Review the changes before commit.
- Commit the changes and push the code to the remote repository.
- Commit the changes and feels like changing again, modify the changes, commit again and push the changes.
# add new group
groupadd dev
# add new user
useradd -G devs -d /home/gituser -m -s /bin/bash gituser
# change password
passwd gituser
//Output of the above command will produce
Changing password for user gituser.
New password:
Retype new password:
passwd: all authentication token updated successfully.Let us initialize a new repository by using init command followed by --bare option. It initializes the repository without a working directory. By convention, the bare repository must be named as .git.
$ pwd
/home/gituser
$ mkdir project.git
$ cd project.git/
$ ls
$ git --bare init
Initialized empty Git repository in /home/gituser-m/project.git/
$ ls
branches config description HEAD hooks info objects refs$ pwd
/home/gituser
$ mkdir gituser_repo
$ cd gituser_repo/
$ git init
Initialized empty Git repository in /home/gituser/gituser_repo/.git/
$ echo 'TODO: Add contents for README' > README
$ git status -s
?? README
$ git add .
$ git status -s
A README
$ git commit -m 'Initial commit'checks the log message by executing the git log command.
$ git log
commit 19ae20683fc460db7d127cf201a1429523b0e319
Author: gituser <gituser@xyz.com>
Date: Wed Jan 15 07:32:56 2017 +0530
Initial commitNote:< F438 /b>
By default, Git pushes only to matching branches: For every branch that exists on the local side, the remote side is updated if a branch with the same name already exists there. In our tutorials, every time we push changes to the origin master branch, use appropriate branch name according to your requirement.
$ git remote add origin gituser@git.server.com:project.git
$ git push origin master
//After execution output looks like this
Counting objects: 3, done.
Writing objects: 100% (3/3), 242 bytes, done.
Total 3 (delta 0), reused 0 (delta 0)
To gituser@git.server.com:project.git
* [new branch]
master −> mastermkdir gituser_repo
cd gituser_repo/
$ git clone gituser@git.server.com:project.gitThe above command will produce the following result.
Initialized empty Git repository in /home/gituser/gituser_repo/project/.git/
remote: Counting objects: 3, done.
Receiving objects: 100% (3/3), 241 bytes, done.
remote: Total 3 (delta 0), reused 0 (delta 0)Suppose I have added a content in a file called test.js.
$ git status -s
?? test.js
$ git add string.c
Git is showing a question mark before file names. Obviously, these files are not a part of Git, and that is why Git does not know what to do with these files. That is why, Git is showing a question mark before file names.
gituser has added the file to the stash area, git status command will show files present in the staging area.
$ git status -s
A test.jsTo commit the changes, he used the git commit command followed by –m option. If we omit –m option. Git will open a text editor where we can write multiline commit message.
$ git commit -m 'Implemented function of one testcase'The above commit will produce the following result
[master cbe1249] Implemented function of one testcase
1 files changed, 24 insertions(+), 0 deletions(-)
create mode 100644 test.jsAfter commit to view log details, he runs the git log command. It will display the information of all the commits with their commit ID, commit author, commit date and SHA-1 hash of commit.
After viewing the commit details, gituser realizes that the string length cannot be negative, that’s why he decides to change the return type of one function.
gituser uses the git log command to view log details.
$ git logThe above command will produce the following result.
commit cbe1249b140dad24b2c35b15cc7e26a6f02d2277
Author: gituser <gituser@xyz.com>
Date: Wed Sep 11 08:05:26 2013 +0530
Implemented function of one testcasegituser uses the git show command to view the commit details. The git show command takes SHA-1 commit ID as a parameter.
$ git show cbe1249b140dad24b2c35b15cc7e26a6f02d2277The above command will produce the following ouput
commit cbe1249b140dad24b2c35b15cc7e26a6f02d2277
Author: gituser <gituser@xyz.com>
Date: Wed Sep 11 08:05:26 2013 +0530
Implemented my_strlen function
diff --git a/test.js b/test.js
new file mode 100644
index 0000000..187afb9
--- /dev/null
+++ b/test.js
@@ -0,0 +1,24 @@
+var testCondition = false;
+
+function testCaseExecution()
+{
+
testCondition = true;
+
+
if (testCondition){
+ executeSanityTesting();
+
}
}
+gituser adds an else part to the above code, user reviews the code by running the git diff command.
$ git diffThe above command will produce the following result.
diff --git a/test.js b/test.js
index 187afb9..7da2992 100644
--- a/test.js
+++ b/test.js
@@ -1,6 +1,6 @@
var testCondition = false;
function testCaseExecution()
{
testCondition = true;
if (testCondition){
executeSanityTesting();
-}
+}else{
+ passTheTestCase();
+}
}Git diff shows '+' sign before lines, which are newly added and '−' for deleted lines.
gituser has already committed the changes and he wants to correct his last commit. In this case, git amend operation will help. The amend operation changes the last commit including your commit message; it creates a new commit ID.
Before amend operation, he checks the commit log.
$ git logThe above command will produce the following result.
commit cbe1249b140dad24b2c35b15cc7e26a6f02d2277
Author: gituser <gituser@xyz.com>
Date: Wed Sep 11 08:05:26 2013 +0530
Implemented function of one testcase functiongituser commits the new changes with -- amend operation and views the commit log.
$ git status -s
M test.js
$ git add test.c
$ git status -s
M test.js
$ git commit --amend -m 'Added else part for the the same function.'
[master d1e19d3] Added else part for the the same function.
1 files changed, 24 insertions(+), 0 deletions(-)
create mode 100644 test.jsgituser modified his last commit by using the amend operation and he is ready to push the changes. The Push operation stores data permanently to the Git repository. After a successful push operation, other developers can see gituser's changes.
gituser is ready to push the code.
$ git push origin masterThe above command will produce the following result:
Counting objects: 4, done.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 517 bytes, done.
Total 3 (delta 0), reused 0 (delta 0)
To gituser@git.server.com:project.git
19ae206..d1e19d3 master −> mastergituser executes the git pull command to synchronize his local repository with the remote one.
$ git pullThe above command will produce the following result:
remote: Counting objects: 5, done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 3 (delta 1), reused 0 (delta 0)
Unpacking objects: 100% (3/3), done.
From git.server.com:project
d1e19d3..cea2c00 master −> origin/master
First, rewinding head to replay your work on top of it...
Applying: Added testcasePass functionSuppose you are implementing a new feature for your product. Your code is in progress and suddenly a customer escalation comes. Because of this, you have to keep aside your new feature work for a few hours. You cannot commit your partial code and also cannot throw away your changes. So you need some temporary space, where you can store your partial changes and later on commit it.
In Git, the stash operation takes your modified tracked files, stages changes, and saves them on a stack of unfinished changes that you can reapply at any time.
$ git status -s
M test.jsNow, you want to switch branches for customer escalation, but you don’t want to commit what you’ve been working on yet; so you’ll stash the changes. To push a new stash onto your stack, run the git stash command.
$ git stash
Saved working directory and index state WIP on master: e86f062 Added testcasePass function
HEAD is now at e86f062 Added testcasePass functionNow, your working directory is clean and all the changes are saved on a stack. Let us verify it with the git status command.
$ git status -s
Nothing pops up.Now you can safely switch the branch and work elsewhere. We can view a list of stashed changes by using the git stash list command.
$ git stash list
stash@{0}: WIP on master: e86f062 Added testcasePass functionSuppose you have resolved the customer escalation and you are back on your new feature looking for your half-done code, just execute the git stash pop command, to remove the changes from the stack and place them in the current working directory.
$ git status -s
Nothing pops up.
$ git stash pop
M test.jsAs the name suggests, the move operation moves a directory or a file from one location to another. user decides to move the source code into src directory. The modified directory structure will appear as follows:
$ pwd
/home/user/project
$ ls
README test test.js
$ mkdir src
git mv test.js src/
$ git status -s
R test.js −> src/test.jsTo make these changes permanent, we have to push the modified directory structure to the remote repository so that other developers can see this.
$ git commit -m "Modified directory structure"
[master 7d9ea97] Modified directory structure
1 files changed, 0 insertions(+), 0 deletions(-)
rename test.js => src/test.js (100%)
$ git push origin master
Counting objects: 4, done.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 320 bytes, done.
Total 3 (delta 0), reused 0 (delta 0)
To gituser@git.server.com:project.git
e86f062..7d9ea97 master −> master$ pwd
/home/gituser/project/src
$ ls
test.js test123.js
$ git log
commit 29af9d45947dc044e33d69b9141d8d2dad37cc62
Author: gituser <gituser123@xyz.com>
Date: Wed Sep 11 10:16:25 2013 +0530
Added a file test123To remove the file git rm can be used.
$ git rm test123.js
rm 'src/test123.js'
$ git commit -a -m "Removed the file successfully"
[master 5776472] Removed the file successfully
1 files changed, 0 insertions(+), 0 deletions(-)
delete mode 100755 src/test123.jsNow ready to push the code.
$ git push origin masterWe have seen that when we perform an add operation, the files move from the local repository to the stating area. If a user accidently modifies a file and adds it into the staging area, he can revert his changes, by using the git checkout command.
In Git, there is one HEAD pointer that always points to the latest commit. If you want to undo a change from the staged area, then you can use the git checkout command, but with the checkout command, you have to provide an additional parameter, i.e., the HEAD pointer. The additional commit pointer parameter instructs the git checkout command to reset the working tree and also to remove the staged changes.
Let us suppose gituser modifies a file from his local repository. If we view the status of this file, it will show that the file was modified but not added into the staging area.
$ pwd
/home/gituser/gituser_repo/project/src
$ git status -s
M test123.js
git add string_operations.cGit status shows that the file is present in the staging area, now revert it by using the git checkout command and view the status of the reverted file.
$ git checkout HEAD -- string_operations.c
$ git status -s
Nothing popups
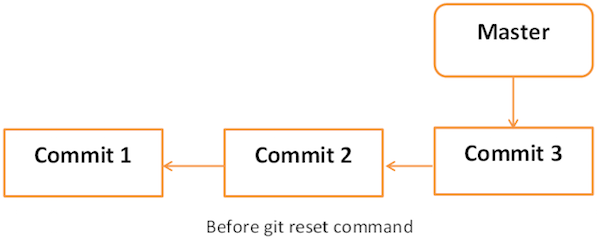
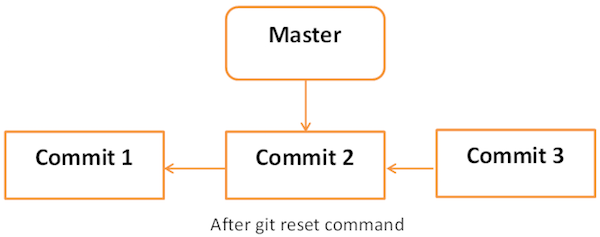
Each branch has a HEAD pointer, which points to the latest commit. If we use Git reset command with --soft option followed by commit ID, then it will reset the HEAD pointer only without destroying anything.
git/refs/heads/master file stores the commit ID of the HEAD pointer. We can verify it by using the git log -1 command.
$ cat .git/refs/heads/master
577647211ed44fe2ae479427a0668a4f12ed71a1Now, view the latest commit ID, which will match with the above commit ID.
$ git log -2The above command will produce the following result.
commit 577647211ed44fe2ae479427a0668a4f12ed71a1
Author: gituser <gituser@xyz.com>
Date: Wed Sep 11 10:21:20 2017 +0530
Removed the file successfully
commit 29af9d45947dc044e33d69b9141d8d2dad37cc62
Author: gituser123
E22E
<gituser123@xyz.com>
Date: Wed Sep 11 10:16:25 2017 +0530
Added testPass functionLet us reset the HEAD pointer.
$ git reset --soft HEAD~Now, we just reset the HEAD pointer back by one position. Let us check the contents of .git/refs/heads/master file.
$ cat .git/refs/heads/master
29af9d45947dc044e33d69b9141d8d2dad37cc62Git reset with --mixed option reverts those changes from the staging area that have not been committed yet. It reverts the changes from the staging area only. The actual changes made to the working copy of the file are unaffected. The default Git reset is equivalent to the git reset -- mixed.
If you use --hard option with the Git reset command, it will clear the staging area; it will reset the HEAD pointer to the latest commit of the specific commit ID and delete the local file changes too.
If Git status is showing that the file is present in the staging area. Now, reset HEAD with -- hard option.
$ git reset --hard 577647211ed44fe2ae479427a0668a4f12ed71a1
HEAD is now at 5776472 Removed the file successfully.Tag operation allows giving meaningful names to a specific version in the repository.
Suppose gituser1 and gituser2 to tag their project code so that they can later access it easily.
Let us tag the current HEAD by using the git tag command. gituser1 provides a tag name with -a option and provides a tag message with –m option.
$ pwd
/home/gituser/gituser_repo/project
$ git tag -a 'Release_1_0' -m 'Tagged basic string operation code' HEADIf you want to tag a particular commit, then use the appropriate COMMIT ID instead of the HEAD pointer. gituser1 uses the following command to push the tag into the remote repository.
$ git push origin tag Release_1_0
Counting objects: 1, done.
Writing objects: 100% (1/1), 183 bytes, done.
Total 1 (delta 0), reused 0 (delta 0)
To gituser@git.server.com:project.git
* [new tag]
Release_1_0 −> Release_1_0gituser1 created tags. Now, gituser2 can view all the available tags by using the Git tag command with –l option.
$ git tag -l
Release_1_0gituser1 uses the Git show command followed by its tag name to view more details about tag.
$ git show Release_1_0
tag Release_1_0
Tagger: gituser1 <gituser1@xyz.com>
Date: Wed Sep 11 13:45:54 2017 +0530
Tagged basic string operation code
commit 577647211ed44fe2ae479427a0668a4f12ed71a1
Author: gituser1 <gituser1@xyz.com>
Date: Wed Sep 11 10:21:20 2017 +0530
Removed the file successfully
diff --git a/src/test123 b/src/test123
deleted file mode 100755
index 654004b..0000000
Binary files a/src/test123 and /dev/null differgituser1 uses the following command to delete tags from the local as well as the remote repository.
$ git tag
Release_1_0
$ git tag -d Release_1_0
Deleted tag 'Release_1_0' (was 0f81ff4)
# Remove tag from remote repository.
$ git push origin :Release_1_0
To gituser@git.server.com:project.git
- [deleted]
Release_1_0Branch operation allows creating another line of development. We can use this operation to fork off the development process into two different directions. For example, we released a product for 6.0 version and we might want to create a branch so that the development of 7.0 features can be kept separate from 6.0 bug fixes.
gituser1 creates a new branch using the git branch command. We can create a new branch from an existing one. We can use a specific commit or tag as the starting point. If any specific commit ID is not provided, then the branch will be created with HEAD as its starting point.
$ git branch new_branch
$ git branch
* master
new_branchA new branch is created; gituser1 used the git branch command to list the available branches. Git shows an asterisk mark before currently checked out branch.
The pictorial representation of create branch operation is shown below:
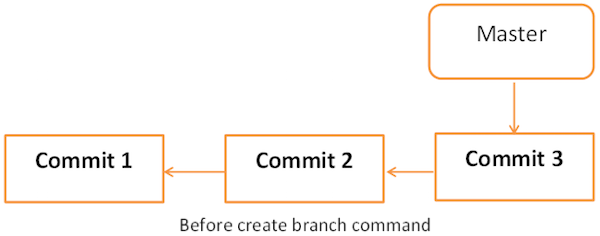
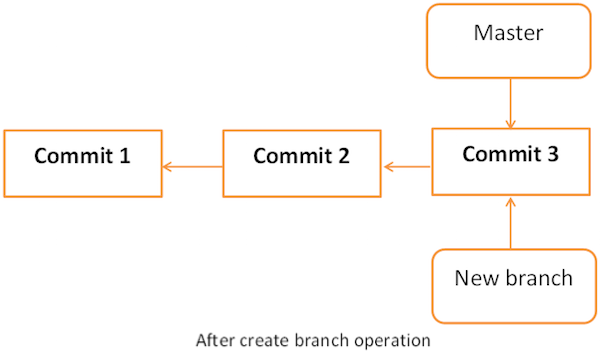
$ git checkout new_branch
Switched to branch 'new_branch'
$ git branch
master
* new_branchGit provides –b option with the checkout command; this operation creates a new branch and immediately switches to the new branch.
$ git checkout -b test_branch
Switched to a new branch 'test_branch'
$ git branch
master
new_branch
* test_branchA branch can be deleted by providing –D option with git branch command. But before deleting the existing branch, switch to the other branch.
$ git branch
master
new_branch
* test_branch
$ git checkout master
Switched to branch 'master'
$ git branch -D test_branch
Deleted branch test_branch (was 5776472).Now, Git will show only two branches.
$ git branch
* master
new_branchuser decides to add support for wide characters in his string operations project. He has already created a new branch, but the branch name is not appropriate. So he changes the branch name by using –m option followed by the old branch name and the new branch name.
$ git branch
* master
new_branch
$ git branch -m new_branch wchar_supportNow, the git branch command will show the new branch name.
$ git branch
* master
wchar_support$ git branch
master
* wchar_support
$ git checkout master
$ git merge origin/wchar_support
Updating 5776472..64192f9
Fast-forward
src/test123.js | 10 ++++++++++
1 files changed, 10 insertions(+), 0 deletions(-)The Git rebase command is a branch merge command, but the difference is that it modifies the order of commits.
The Git merge command tries to put the commits from other branches on top of the HEAD of the current local branch. For example, your local branch has commits A−>B−>C−>D and the merge branch has commits A−>B−>X−>Y, then git merge will convert the current local branch to something like A−>B−>C−>D−>X−>Y
The Git rebase command tries to find out the common ancestor between the current local branch and the merge branch. It then pushes the commits to the local branch by modifying the order of commits in the current local branch. For example, if your local branch has commits A−>B−>C−>D and the merge branch has commits A−>B−>X−>Y, then Git rebase will convert the current local branch to something like A−>B−>X−>Y−>C−>D.
When multiple developers work on a single remote repository, you cannot modify the order of the commits in the remote repository. In this situation, you can use rebase operation to put your local commits on top of the remote repository commits and you can push these changes.
GNU/Linux and Mac OS uses line-feed (LF), or new line as line ending character, while Windows uses line-feed and carriage-return (LFCR) combination to represent the line-ending character.
To avoid unnecessary commits because of these line-ending differences, we have to configure the Git client to write the same line ending to the Git repository.
For Windows system, we can configure the Git client to convert line endings to CRLF format while checking out, and convert them back to LF format during the commit operation. The following settings will do the needful.
$ git config --global core.autocrlf trueFor GNU/Linux or Mac OS, we can configure the Git client to convert line endings from CRLF to LF while performing the checkout operation.
$ git config --global core.autocrlf input