Drew A. Hudson & Christopher D. Manning
Please note: We have updated the challenge deadline to be May 15. Best of Luck! :)
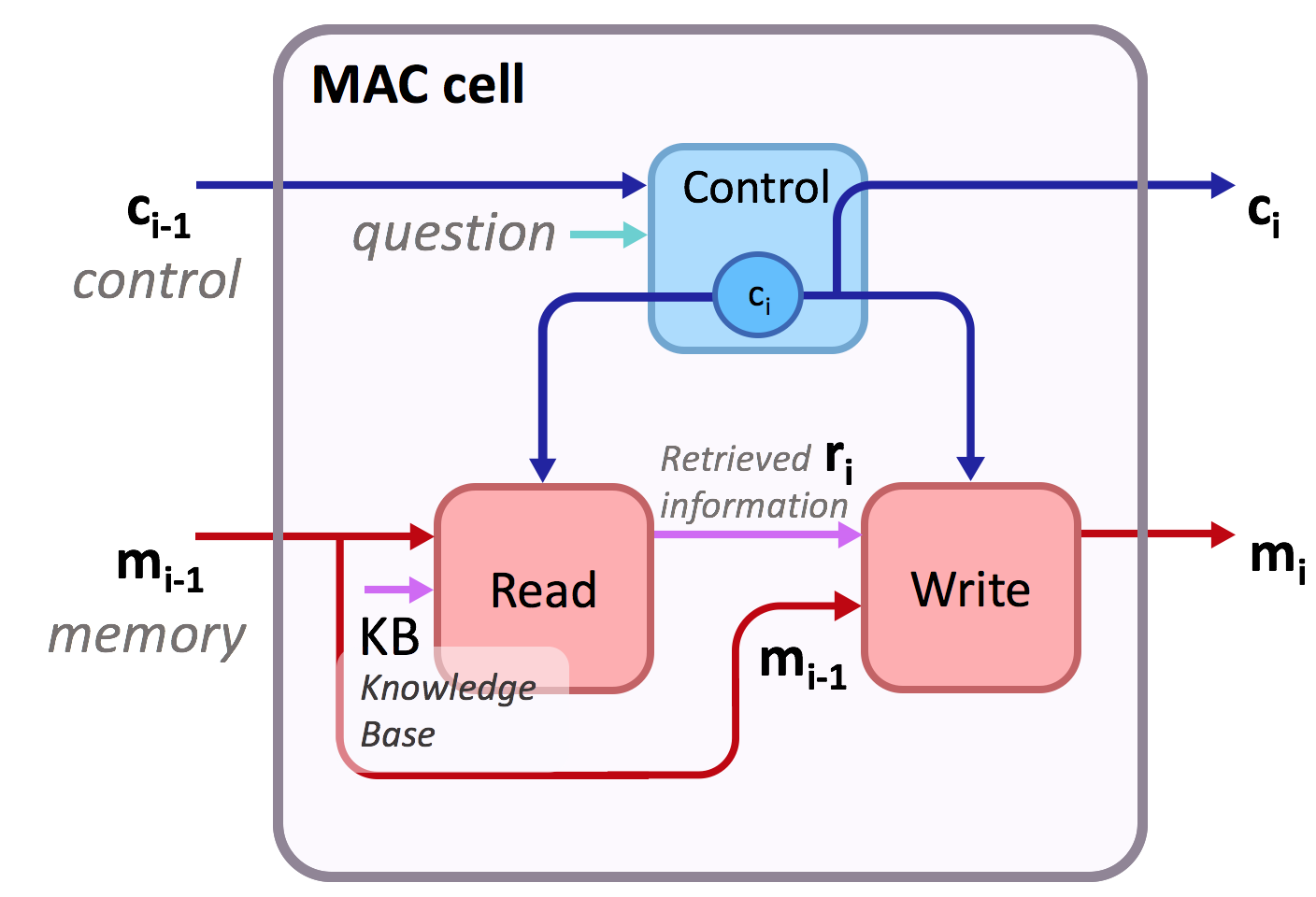
This is the implementation of Compositional Attention Networks for Machine Reasoning (ICLR 2018) on two visual reasoning datasets: CLEVR dataset and the New GQA dataset (CVPR 2019). We propose a fully differentiable model that learns to perform multi-step reasoning. See our website and blogpost for more information about the model!
This branch also includes an extension of the MAC network to work on the the GQA dataset. GQA is a new dataset for real-world visual reasoning, offrering 20M diverse multi-step questions, all come along with short programs that represent their semantics, and visual pointers from words to the corresponding image regions. Here we extend the MAC network to work over VQA and GQA, and provide multiple baselines as well.
MAC is a fully differentiable model that learns to perform multi-step reasoning. See our website and blogpost for more information about the model, and visit the GQA website for all information about the new dataset, including examples, visualizations, paper and slides.
The adaptation of MAC as well as several baselines for the GQA dataset are located at the GQA branch.

For the GQA dataset:
@article{hudson2018gqa,
title={GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering},
author={Hudson, Drew A and Manning, Christopher D},
journal={Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2019}
}
For MAC:
@article{hudson2018compositional,
title={Compositional Attention Networks for Machine Reasoning},
author={Hudson, Drew A and Manning, Christopher D},
journal={International Conference on Learning Representations (ICLR)},
year={2018}
}
Note: In the original version of the code there was a small typo which led to models looking at the wrong images. It is fixed now, so please make sure to work with the most updated version of the repository. Thanks!
- Tensorflow (originally has been developed with 1.3 but should work for later versions as well).
- We have performed experiments on Maxwell Titan X GPU. We assume 12GB of GPU memory.
- See
requirements.txtfor the required python packages and runpip install -r requirements.txtto install them.
Let's begin from cloning this reponsitory branch:
git clone -b gqa https://github.com/stanfordnlp/mac-network.git
Before training the model, we first have to download the GQA dataset and extract features for the images:
To download and unpack the data, run the following commands:
mkdir -p data/glove
mkdir -p data/gqa
cd data
wget http://nlp.stanford.edu/data/glove.6B.zip
unzip glove.6B.zip -d glove
rm glove.6B.zip
cd gqa
wget https://nlp.stanford.edu/data/gqa/sceneGraphs.zip
unzip sceneGraphs.zip -d sceneGraphs
wget https://nlp.stanford.edu/data/gqa/questions1.3.zip
unzip questions1.3.zip -d questions
wget https://nlp.stanford.edu/data/gqa/allImages.zip
unzip allImages.zip -d images
mv images/objects objects
mv images/spatial spatial
mv images/allImages images
cd ../..wget https://dl.fbaipublicfiles.com/clevr/CLEVR_v1.0.zip
unzip CLEVR_v1.0.zip
mv CLEVR_v1.0 CLEVR_v1
mkdir CLEVR_v1/data
mv CLEVR_v1/questions/* CLEVR_v1/data/
- The data zip file here contains only the minimum information and splits needed to run the model in this repository. To access the full version of the dataset with more information about the questions as well as the test/challenge splits please download the questions from the
official download page. - We have updated the download to be the new version of GQA 1.1.2! It is the same as the previous version but with a new test-dev split.
We also download GloVe word embeddings which we will use in our model. The data directory will hold all the data files we use during training.
Note: data.zip matches the official dataset at visualreasoning.net, but, in order to save space, contains about each question only the information needed to train MAC (e.g. doesn't contain the functional programs).
Both spatial ResNet-101 features as well as object-based faster-RCNN features are available for the GQA train, val, and test images. Download, extract and merge the features through the following commands:
python merge.py --name spatial
python merge.py --name objectsTo extract features for CLEVR:
python extract_features.py --input_image_dir CLEVR_v1/images/train --output_h5_file CLEVR_v1/data/train.h5 --batch_size 32 python extract_features.py --input_image_dir CLEVR_v1/images/val --output_h5_file CLEVR_v1/data/val.h5 --batch_size 32 python extract_features.py --input_image_dir CLEVR_v1/images/test --output_h5_file CLEVR_v1/data/test.h5 --batch_size 32
To train the model, run the following command:
python main.py --expName "gqaExperiment" --train --testedNum 10000 --epochs 25 --netLength 4 @configs/gqa/gqa.txtpython main.py --expName "clevrExperiment" --train --testedNum 10000 --epochs 25 --netLength 4 @configs/args.txtFirst, the program preprocesses the GQA questions. It tokenizes them and maps them to integers to prepare them for the network. It then stores a JSON with that information about them as well as word-to-integer dictionaries in the data directory.
Then, the program trains the model. Weights are saved by default to ./weights/{expName} and statistics about the training are collected in ./results/{expName}, where expName is the name we choose to give to the current experiment.
Here we perform training on the balanced 1M subset of the GQA dataset, rather than the full (unbalanced) training set (14M). To train on the whole dataset add the following flag: --dataSubset all.
- The number of examples used for training and evaluation can be set by
--trainedNumand--testedNumrespectively. - You can use the
-rflag to restore and continue training a previously pre-trained model. - We recommend you to try out varying the number of MAC cells used in the network through the
--netLengthoption to explore different lengths of reasoning processes. - Good lengths for GQA are in the range of 2-6.
See config.py for further available options (Note that some of them are still in an experimental stage).
Other language and vision based baselines are available. Run them by the following commands:
python main.py --expName "gqaLSTM" --train --testedNum 10000 --epochs 25 @configs/gqa/gqaLSTM.txt
python main.py --expName "gqaCNN" --train --testedNum 10000 --epochs 25 @configs/gqa/gqaCNN.txt
python main.py --expName "gqaLSTM-CNN" --train --testedNum 10000 --epochs 25 @configs/gqa/gqaLSTMCNN.txtWe have explored several variants of our model. We provide a few examples in configs/args2-4.txt. For instance, you can run the first by:
python main.py --expName "experiment1" --train --testedNum 10000 --epochs 40 --netLength 6 @configs/args2.txtargs2uses a non-recurrent variant of the control unit that converges faster.args3incorporates self-attention into the write unit.args4adds control-based gating over the memory.
See config.py for further available options (Note that some of them are still in an experimental stage).
To evaluate the trained model, and get predictions and attention maps, run the following:
python main.py --expName "gqaExperiment" --finalTest --testedNum 10000 --netLength 4 -r --getPreds --getAtt @configs/gqa/gqa.txtThe command will restore the model we have trained, and evaluate it on the validation set. JSON files with predictions and the attention distributions resulted by running the model are saved by default to ./preds/{expName}.
- In case you are interested in getting attention maps (
--getAtt), and to avoid having large prediction files, we advise you to limit the number of examples evaluated to 5,000-20,000.
To be able to participate in the GQA challenge and submit results, we will need to evaluate the model on all the questions needed for submission file. Run the following command:
python main.py --expName "gqaExperiment" --finalTest --test --testAll --getPreds --netLength 4 -r --submission --get
5F14
Preds @configs/gqa/gqa.txtThen you'll be able to find the predictions needed to be submitted at the preds directory, which you can then go ahead and submit to the challenge! Best of Luck!
Thank you for your interest in our model and the dataset! Please contact me at dorarad@stanford.edu for any questions, comments, or suggestions! :-)
python visualization.py --expName "clevrExperiment" --tier val(Tier can be set to train or test as well). The script supports filtering of the visualized questions by various ways. See visualization.py for further details.
To get more interpretable visualizations, it is highly recommended to reduce the number of cells to 4-8 (--netLength). Using more cells allows the network to learn more effective ways to approach the task but these tend to be less interpretable compared to a shorter networks (with less cells).
Optionally, to make the image attention maps look a little bit nicer, you can do the following (using imagemagick):
for x in preds/clevrExperiment/*Img*.png; do magick convert $x -brightness-contrast 20x35 $x; done;
Thank you for your interest in our model! Please contact me at dorarad@cs.stanford.edu for any questions, comments, or suggestions! :-)