- Abstract
- Demo Examples
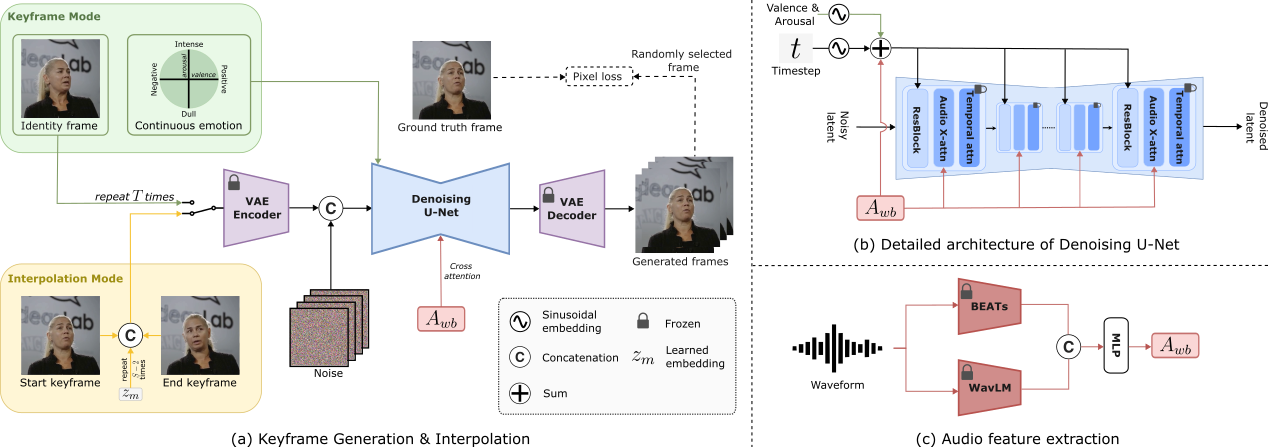
- Architecture
- Installation
- Quick Start Guide
- Advanced Usage
- Citation
- Acknowledgements
Current audio-driven facial animation methods achieve impressive results for short videos but suffer from error accumulation and identity drift when extended to longer durations. Existing methods attempt to mitigate this through external spatial control, increasing long-term consistency but compromising the naturalness of motion. We propose KeyFace, a novel two-stage diffusion-based framework, to address these issues. In the first stage, keyframes are generated at a low frame rate, conditioned on audio input and an identity frame, to capture essential facial expressions and movements over extended periods of time. In the second stage, an interpolation model fills in the gaps between keyframes, ensuring smooth transitions and temporal coherence. To further enhance realism, we incorporate continuous emotion representations and handle a wide range of non-speech vocalizations (NSVs), such as laughter and sighs. We also introduce two new evaluation metrics for assessing lip synchronization and NSV generation. Experimental results show that KeyFace outperforms state-of-the-art methods in generating natural, coherent facial animations over extended durations, successfully encompassing NSVs and continuous emotions.
For more visualizations, please visit https://antonibigata.github.io/KeyFace/
- CUDA-compatible GPU
- Python 3.11
- Conda package manager
# Create conda environment with necessary dependencies
conda create -n keyface python=3.11 nvidia::cuda-nvcc conda-forge::ffmpeg -y
conda activate keyface
# Install requirements
python -m pip install -r requirements.txt --no-deps
# Install PyTorch with CUDA support
python -m pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121If you encounter synchronization issues between omegaconf and antlr4, you can fix them by running:
python -m pip uninstall omegaconf antlr4-python3-runtime -y
python -m pip install "omegaconf==2.3.0" "antlr4-python3-runtime==4.9.3"git lfs install
git clone https://huggingface.co/toninio19/keyface pretrained_modelsThe pretrained models available in the HuggingFace repository have been retrained on non-proprietary data. As a result, the performance and visual quality of animations generated using these models may differ from those presented in the paper.
To use KeyFace with your own data, for simplicity organize your files as follows:
- Place video files (
.mp4) in thedata/videos/directory - Place audio files (
.wav) in thedata/audios/directory
Otherwise you need to specify a different video_dir and audio_dir.
For inference you need to have the audio and video embeddings precomputed.
The simplest way to run inference on your own data is using the infer_raw_data.sh script which will compute those embeddings for you:
bash scripts/infer_raw_data.sh \
--video_dir "data/videos" \
--audio_dir "data/audios" \
--output_folder "my_animations" \
--keyframes_ckpt "path/to/keyframes_model.ckpt" \
--interpolation_ckpt "path/to/interpolation_model.ckpt" \
--compute_until 45This script handles the entire pipeline:
- Extracts video embeddings
- Computes audio embeddings (using BEATS, WavLM, and Wav2Vec2)
- Creates a filelist for inference
- Runs the full animation pipeline
For more control over the inference process, you can directly use the inference.sh script:
bash scripts/inference.sh \
output_folder_name \
path/to/filelist.txt \
path/to/keyframes_model.ckpt \
path/to/interpolation_model.ckpt \
compute_untilThe dataloader needs the path to all the videos you want to train on. Then you need to separate the audio and video as follows:
- root_folder:
- videos: raw videos
- videos_emb: embedding for your videos
- audios: raw audios
- audios_emb: precomputed embeddigns for the audios
You can have different folders but make sure to change them in the training scripts.
KeyFace uses a two-stage model approach. You can train each component separately:
bash train_keyframe.sh path/to/filelist.txt [num_workers] [batch_size] [num_devices]bash train_interpolation.sh path/to/filelist.txt [num_workers] [batch_size] [num_devices]| Parameter | Description | Default |
|---|---|---|
video_dir |
Directory with input videos | data/videos |
audio_dir |
Directory with input audio files | data/audios |
output_folder |
Where to save generated animations | - |
keyframes_ckpt |
Keyframe model checkpoint path | - |
interpolation_ckpt |
Interpolation model checkpoint path | - |
compute_until |
Animation length in seconds | 45 |
For more fine-grained control, you can edit the configuration files in the configs/ directory.
KeyFace can be evaluated using the LipScore metric available in the evaluation/ folder. This metric measures the lip synchronization quality between generated and ground truth videos.
To use the LipScore evaluation, you'll need to install the following dependencies:
- Face detection library: https://github.com/hhj1897/face_detection
- Face alignment library: https://github.com/ibug-group/face_alignment
Once installed, you can use the LipScore class in evaluation/lipscore.py to evaluate your generated animations:
If you use KeyFace in your research, please cite our paper:
@misc{bigata2025keyfaceexpressiveaudiodrivenfacial,
title={KeyFace: Expressive Audio-Driven Facial Animation for Long Sequences via KeyFrame Interpolation},
author={Antoni Bigata and Michał Stypułkowski and Rodrigo Mira and Stella Bounareli and Konstantinos Vougioukas and Zoe Landgraf and Nikita Drobyshev and Maciej Zieba and Stavros Petridis and Maja Pantic},
year={2025},
eprint={2503.01715},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.01715},
}This project builds upon the foundation provided by Stability AI's Generative Models. We thank the Stability AI team for their excellent work and for making their code publicly available.