Crabwalk is a lightweight SQL orchestrator built on top of DuckDB. It processes SQL files in a folder, determines dependencies, and runs them in the correct order.
- SQL Orchestration: Automatically determine the execution order of SQL queries based on dependencies
- Flexible Output Types: Configure outputs as tables, views, or files (Parquet, CSV, JSON)
- Model-level Configuration: Set output types and other options at the model level using SQL comments
- Schema Generation: Generate detailed XML database schema including tables, columns, and relationships
- Column-level Lineage: Track data lineage at the column level to understand data flow
- Schema Visualization: Create interactive HTML visualizations of database schemas and dependencies
- S3 Integration: Backup and restore your DuckDB database to/from S3 (optional)
- Lightweight: Minimal dependencies, fast execution
- Environment Variables: Support for environment variables in SQL queries
# Clone the repository
git clone https://github.com/definite-app/crabwalk.git
cd crabwalk
# Build the project
cargo build --release
# Optional: Build with S3 support
cargo build --release --features s3The project includes a simple example you can run to see Crabwalk in action:
# Clone the repository
git clone https://github.com/definite-app/crabwalk.git
cd crabwalk
# Build and run the example
cargo run # Will use the default-run binary (crabwalk)
# Or specify the binary explicitly
# cargo run --bin crabwalk
# Examine the output lineage diagram
cat examples/simple/lineage.mmd
# Or view the lineage diagram in Mermaid Live Editor via the URL provided in the outputThe example processes these files:
examples/simple/staging/stg_customers.sql- A simple customers tableexamples/simple/staging/stg_orders.sql- A simple orders tableexamples/simple/marts/customer_orders.sql- Joins customers and orders with model-level config:@config: {output: {type: "view"}}examples/simple/marts/order_summary.sql- Creates order metrics by customer with model-level config:@config: {output: {type: "parquet", location: "./output/order_summary.parquet"}}
This example demonstrates several key features:
- Automatic dependency resolution (Crabwalk figures out the correct execution order)
- Model-level configuration through SQL comments
- Support for both tables and views
- Parquet file output
- Lineage diagram generation with Mermaid Live Editor integration
# Run SQL transformations
crabwalk run ./sql --db my_database.duckdb --schema transform
# Use different output types
crabwalk run ./sql --output-type view
crabwalk run ./sql --output-type parquet --output-location ./data/parquet
# Generate database schema XML
crabwalk --schema-only --schema-file schema.xml ./sql
# Generate schema visualization
crabwalk visualize --format html --output schema.html --columns ./sql
# Launch the web application for interactive visualization
crabwalk app --open# Backup the database to S3
crabwalk backup --db my_database.duckdb --bucket my-bucket --access-key XXX --secret-key YYY
# Restore the database from S3
crabwalk restore --db my_database.duckdb --bucket my-bucket --access-key XXX --secret-key YYYYou can configure models directly in SQL files using comments:
-- @config: {output: {type: "view"}}
SELECT * FROM source_table
-- Or for file outputs:
-- @config: {output: {type: "parquet", location: "./output/custom_{table_name}.parquet"}}
SELECT * FROM source_table- Crabwalk analyzes SQL files in the specified folder
- It parses the SQL syntax to extract table dependencies
- It builds a directed graph of dependencies and performs a topological sort
- It executes the SQL files in the correct order
- It creates outputs based on configuration (tables, views, or files)
- Only DuckDB is supported as the backend/dialect
- Python transformations are not yet supported
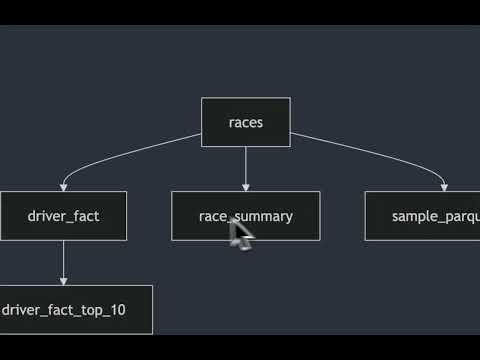
Crabwalk automatically generates lineage diagrams to visualize dependencies between your SQL models:
# Generate lineage diagram for SQL files in a directory
crabwalk --lineage-only ./sql_folderThis creates:
- A
lineage.mmdfile in the specified directory containing the Mermaid diagram definition - A Mermaid Live Editor URL that allows you to view and edit the diagram in your browser
Example diagram:
graph TD
customer_orders
stg_orders
stg_customers
order_summary
stg_orders --> customer_orders
stg_customers --> customer_orders
stg_orders --> order_summary
The generated URL uses proper compression and encoding to ensure it works correctly with the Mermaid Live Editor.
Crabwalk can generate detailed XML database schemas that include table structures, column information, and dependencies:
# Generate schema XML file
crabwalk --schema-only --schema-file schema.xml ./sql_folderThis creates an XML file with:
- Detailed table definitions
- Column information including data types and relationships
- Source dependencies between tables
- Lineage information showing data transformations
For a simple way to visualize your schema, use the visualization tool to generate static HTML:
# Generate HTML schema visualization with column-level details
crabwalk visualize --format html --output schema.html --columns ./sql_folderThe visualization tool provides:
- Interactive HTML view of your database schema
- Table and column details in a readable format
- Entity-relationship diagram using Mermaid
- Column-level lineage tracking (with
--columnsflag) - Export options for SVG and PNG
For a fully interactive experience, Crabwalk includes a web application:
# Launch the web application
crabwalk app
# Launch with a specific port
crabwalk app --port 8080
# Launch and automatically open in your browser
crabwalk app --openThe web application allows you to:
- Upload and view schema XML files
- Visualize Mermaid lineage diagrams
- Browse SQL files
- Explore your data transformations in a user-friendly interface
- Visualize column-level relationships
- Share visualizations with your team
- The "error code: 0" messages in the output are from DuckDB and indicate successful operations. These can be safely ignored.
MIT License