


This mini-project aims to realize a real-time vision application with visual increase of the real scene to enrich the rendering.
Images from the Voc2007 Pascal dataset are used to define reference images that will be identified and tracked in real time. For more info about Voc2007 Pascal dataset please check this link.
The objective is to detect the images in a real-time or pre-recorded video stream. Thus, it is requested to propose and develop a solution that allows the recognition and localization of several classes of images in a tracking process.
- What is Object detection?
- Single-shot object detection
- Two-shot object detection
- What is YOLO?
- Steps
- Performances
What is object detection? Object detection is a computer vision task that involves identifying and locating objects in images or videos. It is an important part of many applications, such as surveillance, self-driving cars, or robotics. Object detection algorithms can be divided into two main categories: single-shot detectors and two-stage detectors.

Single-shot object detection uses a single pass of the input image to make predictions about the presence and location of objects in the image. It processes an entire image in a single pass, making them computationally efficient. However, single-shot object detection is generally less accurate than other methods, and it’s less effective in detecting small objects. Such algorithms can be used to detect objects in real time in resource-constrained environments. YOLO is a single-shot detector that uses a fully convolutional neural network (CNN) to process an image. We will dive deeper into the YOLO model in the next section.
Two-shot object detection uses two passes of the input image to make predictions about the presence and locati 9B3B on of objects. The first pass is used to generate a set of proposals or potential object locations, and the second pass is used to refine these proposals and make final predictions. This approach is more accurate than single-shot object detection but is also more computationally expensive. Overall, the choice between single-shot and two-shot object detection depends on the specific requirements and constraints of the application. Generally, single-shot object detection is better suited for real-time applications, while two-shot object detection is better for applications where accuracy is more important.
You Only Look Once (YOLO) proposes using an end-to-end neural network that makes predictions of bounding boxes and class probabilities all at once. It differs from the approach taken by previous object detection algorithms, which repurposed classifiers to perform detection.
Following a fundamentally different approach to object detection, YOLO achieved state-of-the-art results, beating other real-time object detection algorithms by a large margin.
While algorithms like Faster RCNN work by detecting possible regions of interest using the Region Proposal Network and then performing recognition on those regions separately, YOLO performs all of its predictions with the help of a single fully connected layer. Methods that use Region Proposal Networks perform multiple iterations for the same image, while YOLO gets away with a single iteration.

Yolo divides a picture into a grid of NxM cells. For each cell, it tries to predict a bounding box for an object that would be centered in that cell.
The predicted bounding box can be larger than the cell from which it originates; the only constraint is that the center of the box is somewhere inside the cell.
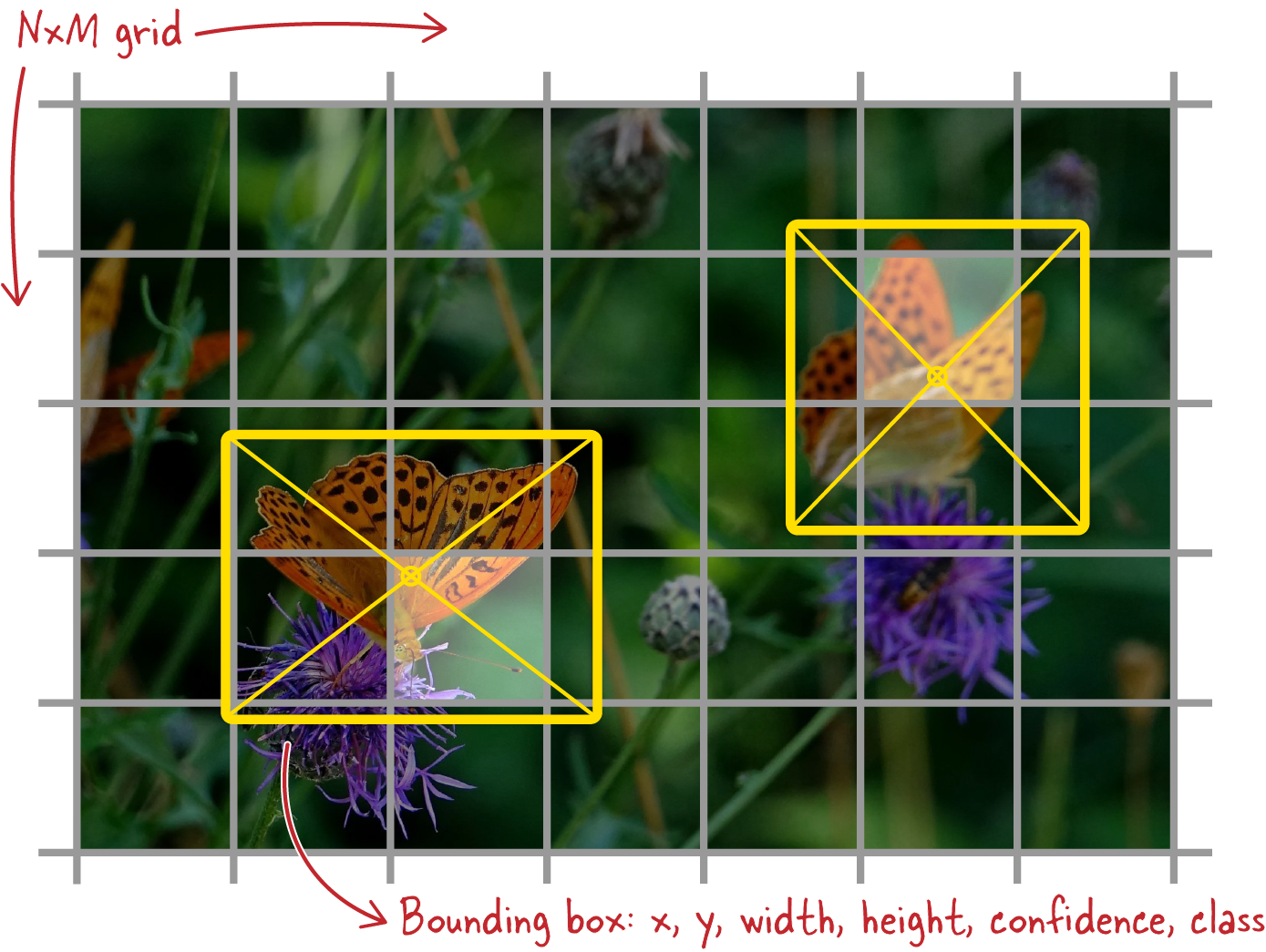
Predicting a bounding box amounts to predicting six numbers: the four coordinates of the bounding box (in this case, the x and y coordinates of the center, and the width and height), a confidence factor which tells us if an object has been detected or not, and finally, the class of the object (for example, “butterfly”). The YOLO architecture does this directly on the last feature map, as generated by the convolutional backbone it is using.
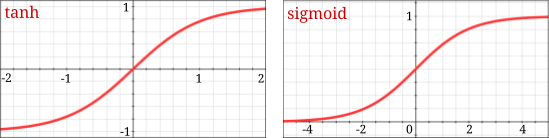
In this figure, the x- and y-coordinate calculations use a hyperbolic tangent (tanh) activation so that the coordinates fall in the [–1, 1] range. They will be the coordinates of the center of the detection box, relative to the center of the grid cell they belong to.

Width and height (w, h) calculations use a sigmoid activation so as to fall in the [0, 1] range. They will represent the size of the detection box relative to the entire image. This allows detection boxes to be bigger than the grid cell they originate in. The confidence factor, C, is also in the [0, 1] range. Finally, a softmax activation is used to predict the class of the detected object.
In object detection, as in any supervised learning setting, the correct answers are provided in the training data: ground truth boxes and their classes. During training the network predicts detection boxes, and it has to take into account errors in the boxes’ locations and dimensions as well as misclassification errors, and also penalize detections of objects where there aren’t any. The first step, though, is to correctly pair ground truth boxes with predicted boxes so that they can be compared. In the YOLO architecture, if each grid cell predicts a single box, this is straightforward. A ground truth box and a predicted box are paired if they are centered in the same grid cell.
However in the YOLO architecture, the number of detection boxes per grid cell is a parameter. It can be more than one. It’s easy enough for each grid cell to predict 10 or 15 (x, y, w, h, C) coordinates instead of 5 and generate 2 or 3 detection boxes instead of 1. But pairing these predictions with ground truth boxes requires more care. This is done by computing the intersection over union between all ground truth boxes and all predicted boxes within a grid cell, and selecting the pairings where the IOU is the highest.

To test YOLOv4 in real time on a video, the YOLOv4-leaky version is used.
YOLOv4-leaky is efficient in terms of accuracy and more flexible on CPU computing time (from 4GB-RAM GPUs). We will use pre-trained model on a base of images of 80 categories whose names are saved in the classes file.txt. The weight and configuration files are respectively: yolov4-leaky.weights and yolov4-leaky.cfg.
The input image of the neural network must be in a certain format called a blob. Once the image is read from the video stream, it is transmitted to the blobFromImage function to convert it into a blob object used as input to the network. In this process, the model normalizes the image and resizes to a given size. The average is set by default and the swapRB parameter is set to true because OpenCV uses BGR images. The output blob object is then transmitted to the network by the setInput function to obtain a list of blobs. These blobs are then processed in order to filter out those with low confidence scores.
The model produces bounding boxes of outputs which are represented by a vector of 5 elements, plus the number of classes. The first 4 elements represent the center x, the center y, the width and the height of the bounding box. The fifth element represents the certainty of the box to encompass an object. The rest of the elements are the associated trust for each object class. The bounding box is assigned to the class corresponding to the highest score. The bounding boxes are then filtered using the confidence threshold, they are subjected to the non-maximum deletion to eliminate the overlapping ones.
Improves YOLOv3’s AP and FPS by 10% and 12%, respectively[5]
