Yuzhang Shang*, Mu Cai*, Bingxin Xu, Yong Jae Lee^, Yan Yan^
*Equal Contribution, ^Equal Advising
[Paper] [Project Page]
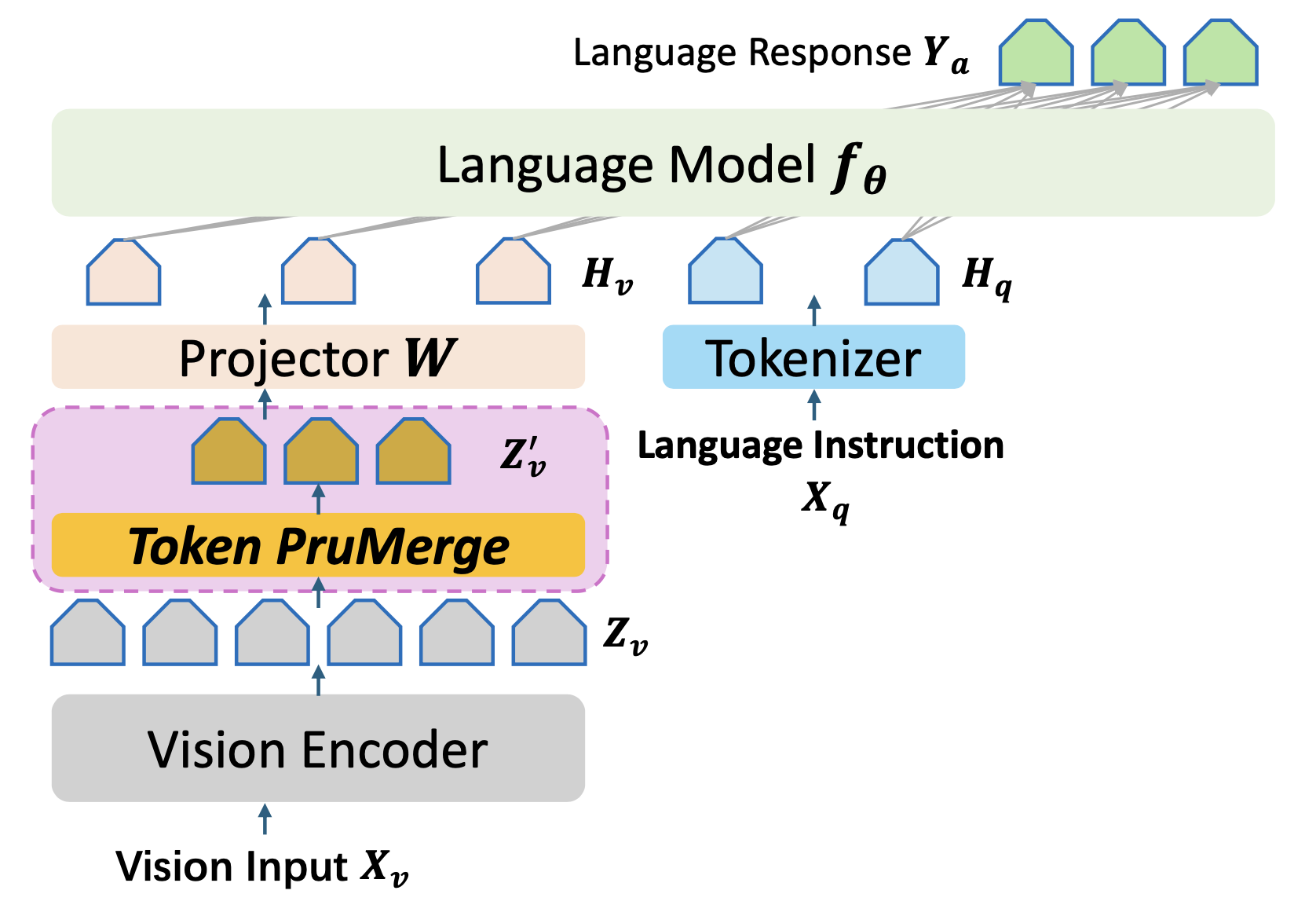
Note that the core of our proposed module is here in the CLIP image encoder.
Download the checkpoints (LoRA Version) from Yuzhang's Huggingface Homepage to checkpoints/llava-v1.5-7b-lora-prunemerge.
Change the call function of token reduction from here in the CLIP image encoder.
For example, the evaluation for TextVQA is:
CUDA_VISIBLE_DEVICES=7 XDG_CACHE_HOME='/data/shangyuzhang/' bash scripts/v1_5/eval/testvqa.shFor other inference scripts, refer to LLaVA Evaluation.
If you find our code useful for your research, please cite our paper.
@inproceedings{
shang2025prumerge,
title={LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models},
author={Yuzhang Shang and Mu Cai and Bingxin Xu and Yong Jae Lee and Yan Yan},
booktitle={ICCV},
year={2025}
}