Tags: mpotter/parquetjs
Tags
Support bloom filters in lists/nested columns (LibertyDSNP#105) For bloom filters, treat column names as the full path and not just the first part of the path in the schema. Closes LibertyDSNP#98 with @rlaferla Co-authored-by: Wil Wade <wil.wade@unfinished.com>
Add support to byte array decimal fields (LibertyDSNP#97) Problem ======= Address LibertyDSNP#91 Solution ======== When encountering such byte array represented "Decimal" fields, parse them into raw buffers. Change summary: --------------- - Added code to parse "Decimal" type fields represented by byte arrays (fixed length or non-fixed length) into raw buffer values for further client side processing. - Added two test cases verifying the added code. - Loosen the precision check to allow values greater than 18 for byte array represented "Decimal" fields. Steps to Verify: ---------------- - Use the library to open a parquet file which contains a "Decimal" field represented by a byte array whose precision is greater than 18. - Before the change, library will throw an error saying precision cannot be greater than 18. - After the change, library will parse those fields to their raw buffer values and return records normally. --------- Co-authored-by: Wil Wade <wil.wade@unfinished.com>
Feature: Timestamp support for JSONSchema generated schemas (LibertyD… …SNP#95) Problem ======= Closes: LibertyDSNP#93 Solution ======== Add checks for `format == 'date-time`` inside the string type check for`string` and `array of string` Change summary: --------------- * Added format check for string fields ( and string arrays ) * Check for JSONSchema property `format` with value `date-time` * Updated jsonschema tests and updated the snapshots Steps to Verify: ---------------- 1. Generate a JSON Schema or use an existing one 2. Add `"format":"date-time"` to the field which should have a Date/Time value 3. Ensure that the value is a valid `Date` object 4. Enjoy
Add null pages and boundary order (Fixes LibertyDSNP#92) (LibertyDSNP#94 ) Problem ======= Parquet file column indexes are required to have `null_pages` and `boundary_order`, but they were missing from Parquetjs generated files. https://github.com/apache/parquet-format/blob/1603152f8991809e8ad29659dffa224b4284f31b/src/main/thrift/parquet.thrift#L955 Closes LibertyDSNP#92 Solution ======== Note: While required, the requirement is not always a hard requirement depending on the library. Steps to Verify: ---------------- 1. Checkout the branch 2. `npm i && npm run build && npm pack ` 3. Install parquet cli tools (macOS brew: `brew install parquet-cli`) 4. Checkout the bug repo from LibertyDSNP#92 https://github.com/noxify/parquetjs_bug/ 5. `cd parquetjs_bug/parquetjs && npm i` 6. `node index.js && parquet column-index ../generated_files/parquetjs/change.parque` will FAIL 7. npm i ../parquetjs/dsnp-parquetjs-0.0.0.tgz 8 `node index.js && parquet column-index ../generated_files/parquetjs/change.parque` will PASS!
Decimal Writer Support (LibertyDSNP#90) Problem ======= Need to support writing decimal types Also closes: LibertyDSNP#87 Solution ======== Add basic encoding support for decimals Change summary: --------------- * Added better decimal field errors * Default scale to 0 per spec * Cleanup types on RLE so it only asks for what is needed * Support decimal encoding * Add test for write / read of decimal Steps to Verify: ---------------- 1. Generate a schema with decimal field 2. Use it!
update to node 16, FIX HASHER BUG (LibertyDSNP#84) Problem ======= We need to update to Node16+ as 15.* is @ end-of-life. Closes LibertyDSNP#62, Fixes LibertyDSNP#85, a hasher bug Solution ======== Update to nodejs 16.15.1, update some packages and fix anything broken. **Important:** This revealed a bug in the Xxhasher code that was not converting to hex-encoded strings as the [bloom filter expects](https://github.com/LibertyDSNP/parquetjs/blob/2c733b5c7a647b9a8ebe9a13d300f41537ef60e2/lib/bloom/sbbf.ts#L357)
Add ability to read decimal columns (LibertyDSNP#79) Problem ======= Often parquet files have a column of type `decimal`. Currently `decimal` column types are not supported for reading. Solution ======== I implemented the required code to allow properly reading(only) of decimal columns without any external libraries. Change summary: --------------- * I made a lot of commits as this required some serious trial and error * modified `lib/codec/types.ts` to allow precision and scale properties on the `Options` interface for use when decoding column data * modified `lib/declare.ts` to allow `Decimal` in `OriginalType`, also modified `FieldDefinition` and `ParquetField` to include precision and scale. * In `plain.ts` I modified the `decodeValues_INT32` and `decodeValues_INT64` to take options so I can determine the column type and if `DECIMAL`, call the `decodeValues_DECIMAL` function which uses the options object's precision and scale configured to decode the column * modified `lib/reader.ts` to set the `originalType`, `precision`, `scale` and name while in `decodePage` as well as `precision` and `scale` in `decodeSchema` to retrieve that data from the parquet file to be used while decoding data for a Decimal column * modified `lib/schema.ts` to indicate what is required from a parquet file for a decimal column in order to process it properly, as well as passing along the `precision` and `scale` if those options exist on a column * adding `DECIMAL` configuration to `PARQUET_LOGICAL_TYPES` * updating `test/decodeSchema.js` to set precision and scale to null as they are now set to for non decimal types * added some Decimal specific tests in `test/reader.js` and `test/schema.js` Steps to Verify: ---------------- 1. Take this code, and paste it into a file at the root of the repo with the `.js` extenstion: ``` const parquet = require('./dist/parquet') async function main () { const file = './test/test-files/valid-decimal-columns.parquet' await _readParquetFile(file) } async function _readParquetFile (filePath) { const reader = await parquet.ParquetReader.openFile(filePath) console.log(reader.schema) let cursor = reader.getCursor() const columnListFromFile = [] cursor.schema.fieldList.forEach((rec, i) => { columnListFromFile.push({ name: rec.name, type: rec.originalType }) }) let record = null let count = 0 const previewData = [] const columnsToRead = columnListFromFile.map(col => col.name) cursor = reader.getCursor(columnsToRead) console.log('-------------------- data --------------------') while (record = await cursor.next()) { previewData.push(record) console.log(`Row: ${count}`) console.log(record) count++ } await reader.close() } main() .catch(error => { console.error(error) process.exit(1) }) ``` 2. run the code in a terminal using `node <your file name>.js` 3. Verify that the schema indicates 4 columns, including `over_9_digits` with scale: 7, and precision 10. As well as a column `under_9_digits` with scale: 4, precision: 6. 4. The values of those columns should match this table: 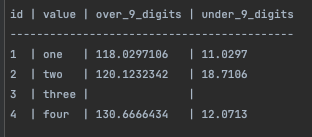
Feature - collect and report multiple field errors (LibertyDSNP#75) Problem ======= This PR is intended to implement 2 enhancements to schema error reporting. * When a parquet schema includes an invalid type, encoding or compression the current error does not indicate which column has the the problem * When a parquet schema has multiple issues, the code currently fails on the first, making multiple errors quite cumbersome Solution ======== Modified the schema.ts and added tests to: * Change error messages from the original `invalid parquet type: UNKNOWN` to `invalid parquet type: UNKNOWN, for Column: quantity` * Keep track of schema errors as we loop through each column in the schema, and at the end, if there are any errors report them all as below: `invalid parquet type: UNKNOWN, for Column: quantity` `invalid parquet type: UNKNOWN, for Column: value` Change summary: --------------- * adding tests and code to ensure multiple field errors are logged, as well as indicating which column had the error * also adding code to handle multiple encoding and compression schema issues Steps to Verify: ---------------- 1. Download this [parquet file](https://usaz02prismdevmlaas01.blob.core.windows.net/ml-job-config/dataSets/multiple-unsupported-columns.parquet?sv=2020-10-02&st=2023-01-09T15%3A28%3A09Z&se=2025-01-10T15%3A28%3A00Z&sr=b&sp=r&sig=GS0Skk93DCn5CnC64DbnIH2U7JhzHM2nnhq1U%2B2HwPs%3D) 2. attempt to open this parquet with this library `const reader = await parquet.ParquetReader.openFile(<path to parquet file>)` 3. You should receive errors for more than one column, which also includes the column name for each error --------- Co-authored-by: Wil Wade <wil.wade@unfinished.com>
Bug/browser types bug LibertyDSNP#70 (LibertyDSNP#71) * Update esbuild * Allow running a specific test file * Build out types for the browser cjs and esm files * Update the README on how to use building
Better handling of millis and micros (LibertyDSNP#68) * Clean up TIMESTAMP issues ZJONSSON#65 ZJONSSON#45 * Use MAX_SAFE_INTEGER for testing toPrimitive_TIME_MILLIS
PreviousNext